Forschungsergebnisse
OLL - Verschriftlichung von Videosequenzen
Zusammenfassung
Im Rahmen des Projekte Online-Lehr- und Lernhilfsmittel (OLL) an der Fachhochschule Brandenburg wurde im Teilprojekt Verschriftlichung von Videosequenzen ein automatisierter Prozess implementiert und erforscht, mit dem eine Verschriftlichung von Videos möglich ist. Neben einem Transkript werden Worthäufigkeitslisten für jedes Video erzeugt. Die Videos können anschließend automatisch einer benutzerdefinierten Anzahl von Kategorien zugeordnet werden. Dadurch ist z.B. die automatische Verschlagwortung und thematische Einordnung von Videomaterial mit unbekanntem gesprochenem Inhalt möglich. Der Prozess wird durch eine grafische Benutzeroberfläche gesteuert. Projekte mit Videos, Kategorien und Steuerparametern können gespeichert und wiederverwendet werden. Die Ergebnisse werden u.a. als HTML5-Webseite und als maschinenlesbares XML ausgeben. Die Webseite bietet eine ansprechende visuelle Aufbereitung der erkannten Worte und Texte und eine übersichtliche Präsentation der Übereinstimmung zwischen den Videos und der Kategorien.
Das Projekt wurde gefördert mit Mitteln des Europäischen Fonds für Regionalentwicklung (EFRE) in der Bewirtschaftung des MWFK Programms “e-learning und e-knowledge”. Das Projekt wird unter der Antragsnummer 80156701 geführt.
Zielstellung
Das Ziel des Teilprojektes ist, das Testen und lauffähig machen eines automatisierten Prozesses zur Extraktion von Tonspuren aus einem Video, Verschriftlichung der Tonspur und Erstellen einer Worthäufigkeitsliste.
Dazu soll zunächst eine Software gefunden und getestet werden, mit der die Tonspur aus einem Video extrahiert und in einem geeigneten Format gespeichert werden kann.
Des Weiteren soll eine Anzahl von unterschiedlicher Diktatsoftware untersucht werden. Zu prüfen ist, ob sich die Software für die Einbindung in einen automatisierten Prozess eignet und wie die Unterstützung für eine Vielzahl unbekannter Sprecher ist.
Die erkannten Worte sollen nach relevanten Worten gefiltert werden. Die Filterung soll durch Parameter gesteuert werden können. Es soll eine Worthäufigkeitsliste und daraus ein Glossar erzeugt werden. Es soll untersucht werden, wie die Worthäufigkeitsliste innerhalb des automatisierten Prozesses durch eine Wortwolke visualisiert werden kann.
Darüber hinaus ist zu prüfen, ob es möglich ist, Links zu erzeugen, die von erkannten Worten aus dem Volltext oder aus dem Glossar zu den Positionen ihres Auftretens im Video führen.
Als weiteres Ziel des Projektes sollen die Videos benutzerdefinierten Kategorien zugeordnet werden. Eine Kategorie soll dabei durch eine Wortliste definiert werden. Im Ergebnis sollen sowohl für ein Video alle zugeordnete Kategorien angezeigt werden, als auch umgekehrt für eine Kategorie alle zugeordneten Videos.
Die Ergebnisse des Prozesses sollen visuell aufbereitet und zusätzlich in einem Format für die weitere maschinelle Verarbeitung gespeichert werden.
Um das Projekt sinnvoll abzugrenzen werden alle Untersuchungen und Entwicklungen auf die deutsche Sprache eingeschränkt.
Die Software die im Rahmen dieses Projektes entsteht, soll als quelloffenes Projekt veröffentlicht werden.
Tonspurextraktion
Für die Verschriftlichung von Videomaterial ist lediglich die Analyse der Tonspur erforderlich. Aus diesem Grund muss diese vor der weiteren Verarbeitung zunächst aus jedem Video extrahiert werden.
Digitales Videomaterial wird in sog. Container-Formaten gespeichert. Beispiele sind AVI, MOV, MP4, MKV. Ein Container-Format enthält i.d.R. Strukturen für Meta-Daten (Urheber, Sprache, etc.) und unterstützt ein oder mehrere Bild- und ein oder mehrere Tonspuren.
Das Verbinden von den digitalen Datenströmen für das Bild und den Ton eines Videos in einem Container wird als muxen bezeichnet, das Trennen von Bild und Tonspur demuxen. Die Bild- und Tonspuren können, um Speicherplatz und Übertragungsbandbreite zu sparen, in komprimierter Form gespeichert werden. Dabei kommen sowohl für Bild- als auch Tonspuren eine Vielzahl von unterschiedlichen verlustfreien und verlustbehafteten Kompressionsverfahren zum Einsatz. Beispiele sind M-JPEG, MPEG-1, MPEG-2, MPEG-4/AVC (H.264) für Bildspuren und FLAC, MP3, AAC (MPEG-4-Audio) für Tonspuren. In einigen Fällen ist es auch sinnvoll Bild- und Tondaten unkomprimiert zu speichern. Jedoch ist auch in diesem Fall ein Container-Format für das muxen erforderlich.
Ist die Tonspur in einem Video mehrkanalig, z.B. im Stereo-Format, sollte die Tonspur vor der Spracherkennung in eine Mono-Tonspur umgewandelt werden.
Für das Speichern einer Tonspur als Audio-Datei sind entsprechend der verschiedenen Kompressionsverfahren auch unterschiedliche Dateiformate üblich. Soll die Tonspur mit einem anderen Kompressionsformat gespeichert werden, als sie in einem Video-Container vorgefunden wurde, muss die Tonspur neu kodiert werden.
Für die Extraktion einer Tonspur aus einem digital gespeicherten Video sind folglich drei Schritte notwendig:
- Tonspur aus Container-Datei extrahieren ( demuxen )
- Tonspur falls erforderlich neu kodieren
- Tonspur in Audio-Datei speichern
Damit eine Software zur Verschriftlichung von Videomaterial eine möglichst große Anzahl der gängigen Container- und Kompressionsformate unterstützt, ist ein Programm erforderlich, welches eine große Anzahl von Container- und Kompressionsformaten lesend unterstützt und Tonspuren in einem für das Spracherkennungssystem verständlichen Format speichern kann.
Das Projekt FFmpeg stellt eine quelloffene und Plattform-unabhängige Lösung für das Aufzeichnen, Konvertieren und Streamen von Audio- und Videomaterial unter der LGPL 2.1 zur Verfügung. FFmpeg enthält die Codec-Bibliothek libavcodec, welche durch die OpenSource-Community gepflegt wird und Bestandteil vieler freier Medienplayer ist. Teil des Projektes ist das Befehlszeilenwerkzeug ffmpeg welches eine automatische Erkennung des Formates einer Videodatei und auch alle drei oben genannten Schritte zur Extraktion der Tonspur beherrscht.
Für das Projekt OLL wird FFmpeg für die Extraktion der Tonspur aus Videos verwendet.
Spracherkennungssysteme
Im folgenden Abschnitt werden zunächst einige Grundlagen zur Spracherkennung und Verschriftlichung erläutert und anschließend ein existierendes Spracherkennungssystem für das Projekt OLL ausgewählt.
Spracherkennung
Hinter dem Begriff Spracherkennung verbergen sich zwei unterschiedliche Zielstellungen. Zum einen gibt es die Spracherkennung auf der Basis einer Grammatik für die Steuerung durch Sprache. Diese Form wird z.B. in Telefonsystemen eingesetzt und zeichnet sich dadurch aus, dass für eine Vielzahl unbekannter Sprecher ein relativ kleiner Wortschatz erkannt und in Steuerbefehle umgesetzt werden soll. Und zum anderen gibt es die Spracherkennung für die Verschriftlichung, auch als Diktiersystem bezeichnet. Diese Form zeichnet sich dadurch aus, dass für einen bekannten Sprecher ein großer Wortschatz erkannt und in einen sauberen Text umgesetzt werden soll.
Für die Verschriftlichung von unbekanntem Videomaterial besteht die besondere Herausforderung darin, dass für eine große Anzahl unbekannter Sprecher ein großer Wortschatz erkannt werden soll. Bereits 1989 wurde dieses Anwendungsfeld mit begrenztem Erfolg erforscht (vergl. (Levinson et al. 1989)). Eine gute Zusammenfassung zu dem aktuellen Forschungsstand findet sich in (G. Saon and Chien 2012).
Methodik und Bausteine
Die aktuellen Spracherkennungssysteme arbeiten überwiegend nach dem folgenden Prinzip. Die Tonspur wird anhand der auftretenden Pausen in Abschnitte unterteilt (Phrasen). Jede Phrase wird nach Lauten durchsucht (Phoneme). Die Laute werden mit Hilfe eines akustischen Modells in ein Lautalphabet, wie das Internationale Phonetische Alphabet (IPA) übersetzt. Dabei werden die Klangeigenschaften (z.B. Frequenzspektrum) als Merkmal verwendet. Die Lautfolgen werden nun benutzt, um Wörter aus einem vorgegebenen Wortschatz auszuwählen. Der Wortschatz kann in Form einer kleinen Grammatik (Befehlssteuerung) oder einem großen Lexikon (Verschriftlichung) definiert sein. Ein Wortschatz wird häufig in der Pronunciation Lexicon Specification (PLS) Notation gespeichert. Um die Laufzeit der Suche in einem großen Wortschatz zu verbessern, wird ein Hidden-Markov-Model (HMM) verwendet. Das HMM gibt die Wahrscheinlichkeit an, mit der ein Wort nach einem bereits erkannten Wort auftritt, dadurch muss für jedes potentielle Wort nur noch ein kleiner Teil des Wortschatzes durchsucht werden.
Dabei treten die folgenden Bausteine auf:
- Akustisches Modell
- Lautalphabet
- Wortschatz
- Hidden-Markov-Model / N-Gramme
Akustisches Modell
Das akustische Modell bildet die Aussprache eines Sprechers und die Klangeigenschaften der Aufnahmetechnik auf ein Lautalphabet ab. Für Spracherkennungssysteme die Verschriftlichung unterstützen, wird für jeden potentiellen Sprecher ein eigenes akustisches Modell als Teil eines Sprecherprofils angelegt. Das akustische Modell wird trainiert, indem der Sprecher einen Text vorliest, dessen Lautfolge dem System bekannt ist.
Seit den 90er Jahren wurden adaptive akustische Modelle erforscht. Das Ziel dieser Modelle ist es, die Erkennungsleistung für einen Sprecher über eine längere Benutzungsphase kontinuierlich zu steigern (vergl. (Thelen 1996)). Des Weiteren wurden Ansätze erforscht, das akustische Modell derart zu normalisieren, dass es in Teilen sprecherunabhängig wird und in Folge keine sprecherspezifische Trainingsphase mehr erforderlich macht (vergl. (Wegmann et al. 1996) und (Lee and Rose 1998)).
Lautalphabet
Ein Lautalphabet ist ein Alphabet welches alle Laute einer vokalen Kommunikationsform enthält. Im Gegensatz zum Alphabet einer Schriftsprache beschreiben die Elemente eines Lautalphabetes nicht die Zeichen aus denen Worte in Schriftform gebildet werden, sondern die kleinsten identifizierbaren Klangelemente die bei der Aussprache eines Wortes verwendet werden.
Ein verbreitetes Lautalphabet ist das Internationale Phonetische Alphabet. Bei einigen Spracherkennungssystemen kommen aber auch herstellerspezifische Lautalphabete zum Einsatz.
Wortschatz
Die Grammatik oder das Lexikon eines Spracherkennungssystems bildet die Lautfolgen einer vokalen Sprache auf die Zeichenfolgen einer Schriftsprache ab. Dabei werden einem Wort der Schriftsprache ein oder mehrere mögliche Lautfolgen zugeordnet. Umgekehrt kann eine Lautfolge aber auch mehreren Worten zugeordnet sein. Der Wortschatz für ein Spracherkennungssystem richtet sich stark nach der Zielstellung der Spracherkennung. So werden für Befehlssteuerungen nur kleine Wortschätze verwendet (Größenordnung 10 - 100 Befehle), während für die Verschriftlichung alle Worte der verwendeten natürlichen Sprache enthalten sein müssen. Der Umfang eines Lexikons für die Verschriftlichung variiert in Abhängigkeit der zu erwartenden Fachdomäne, z.B. Nachrichten, Medizin, Jura (Größenordnung 5.000 - 500.000 Worte).
Je kleiner der Wortschatz ist, desto stärker unterscheiden sich die Lautfolgen der Wörter voneinander. Infolgedessen ist die Erkennung der Worte sicherer. Bei einem großen Wortschatz treten zusätzlich zu mehr Ähnlichkeiten auch zunehmend Homophone (unterschiedliche Wort mit gleicher Aussprache) auf.
Neben der Zuordnung eines Wortes zu ein oder mehreren Lautfolgen gibt ein Wortschatz auch oft die Rolle eines Wortes in der Sprache an (z.B. Substantiv, Adjektiv, Verb). Durch diese Angabe kann Wissen über die Grammatik einer natürlichen Sprache verwendet werden, um aus mehreren möglichen erkannten Worten das wahrscheinlichste auszuwählen.
Zur Speicherung eines Wortschatzes hat sich inzwischen weitgehend die von der W3C herausgegebene Empfehlung Pronunciation Lexicon Specification (PLS) durchgesetzt, welche auf der eXtensible Markup Language (XML) aufsetzt.
Jüngere Ansätze haben die automatische Erkennung von zusammengesetzten Worten, die nicht im Wortschatz enthalten sind, zum Gegenstand (vergl. (George Saon and Padmanabhan 1999)). Des Weiteren werden auch Verfahren untersucht, die den thematischen Kontext einer Phrase bei der Auswahl der erkannten Worte berücksichtigen (vergl. (Bellegarda 2000) und (Wang, McCallum, and Wei 2007)).
Hidden-Markov-Model / N-Gramme
Das HMM für ein Lexikon gibt die Wahrscheinlichkeit für das Auftreten eines Worts an. Dabei wird die Wahrscheinlichkeit in Bezug zu den vorher erkannten Wörtern gesetzt. In diesem Kontext spricht man auch von N-Grammen. Das Hidden-Markov-Model für einen Wortschatz wird i.d.R. aus bereits existierenden Texten gewonnen und erfordert einen rechenintensiven Trainingsprozess.
Systeme
Bei der Recherche im Rahmen des Projektes OLL wurden die folgenden Spracherkennungssysteme gefunden. Dabei wurden nur Systeme berücksichtigt, welche einen Diktiermodus für die Verschriftlichung besitzen.
- Voice Pro (VP) von Linguatec (ehemals Via Voice von IBM)
- Dragon Natural Speaking (DNS) von Nuance Communications
- MS Speech API (SAPI) von Microsoft
- Sphinx von CMU
- Julius von Nagoya Institute of Technology (ehemals von Kyoto University)
Bewertungskriterien
Für die Auswahl eines Systems für die Verschriftlichung von Tonspuren im Projekt OLL werden die folgenden Auswahlkriterien verwendet.
- Einarbeitungsaufwand gering
Der Aufwand für die Einrichtung eines funktionstüchtigen Spracherkennungssystems muss von einem Entwickler im Rahmen der Projektlaufzeit bewältigt werden können. Dabei steht nicht die gesamte Projektlaufzeit für die Einarbeitung in das Spracherkennungssystem zur Verfügung, vielmehr muss sie mit den anderen Teilaufgaben (Tonspurextraktion, Glossar-Generierung, Ergebnisdarstellung, Dokumentation) geteilt werden. - Bausteine verfügbar
Damit eine erfolgreiche Inbetriebnahme des Spracherkennungssystems im Rahmen des Projektes möglich ist, müssen alle Bausteine (akustisches Modell, Lexikon, HMM) für die deutsche Sprache verfügbar sein oder mit vertretbarem Aufwand erstellt werden können. - Technische Voraussetzungen erfüllt
Das Spracherkennungssystem muss auf einem handelsüblichen PC und einem an der Hochschule verfügbaren Betriebssystem lauffähig sein. Dazu gehören z.B. eine aktuelle Linux-Distribution wie SuSE, Fedora oder Ubuntu und Microsoft Windows in den Versionen XP, Vista, 7 und 8. Des Weiteren muss das Spracherkennungssystem durch eine Programmierschnittstelle (API / SDK) angesteuert werden können. - Kosten gering (einmalig, laufend)
Durch das Spracherkennungssystem dürfen keine laufenden Kosten entstehen. Einmalige Lizenzkosten dürfen die Größenordnung von 1000,00 EURO nicht überschreiten. - Transparent
Das System sollte im besten Fall im Quelltext vorliegen und ausreichend dokumentiert sein. - Flexibel
Das System sollte konfigurierbar sein, um eine Optimierung für den konkreten Anwendungsfall zu erleichtern. Dazu sollte es möglich sein, das akustische Modell, den Wortschatz und das HMM auszutauschen oder anzupassen.
Auf das Auswahlkriterium Erkennungsgenauigkeit muss verzichtet werden, da die Systeme in dieser Hinsicht nicht vergleichbar sind. Es existieren keine normierten Testfälle und dazugehörige Testergebnisse für alle Systeme. Die Erarbeitung entsprechender Testfälle und Durchführung der Tests würde den Rahmen des Projektes übersteigen.
Auswahl
Jedes System wird unter jedem Auswahlkriterium mit 0 bis 2 bewertet. Erfüllt ein System ein Kriterium nicht, erhält es 0. Erfüllt ein System ein Kriterium ausreichend, erhält es 1. Erfüllt ein System ein Kriterium in besonderem Maße, erhält es 2.
| Kriterium | VP | DNS | SAPI | Sphinx | Julius |
|---|---|---|---|---|---|
| Einarbeitungsaufwand gering | 1 | 1 | 2 | 0 | 0 |
| Bausteine verfügbar | 2 | 1 | 1 | 0 | 0 |
| Technische Voraussetzungen erfüllt | 1 | 1 | 1 | 1 | 1 |
| Kosten gering | 0 | 0 | 1 | 2 | 2 |
| Transparent | 1 | 1 | 1 | 2 | 2 |
| Flexibel | 1 | 1 | 1 | 2 | 2 |
Die kommerziellen Produkte Voice Pro und Dragon Natural Speaking kommen nicht in Frage, da eine Lizenz, für eine Version die eine stapelweise Verschriftlichung von Tonspuren unterstützt, mehrere tausend Euro kostet. Des Weiteren könnte ein Projektergebnis auf Basis dieser Produkte nicht ohne weiteres von Dritten nachvollzogen werden. Interessant ist Voice Pro von Linguatech dennoch, da es, laut Hersteller-Website, die als bisher sehr schwierig geltende sprecherunabhängige Spracherkennung von allgemeiner Sprache im Diktat beherrschen soll.
Die quelloffenen Projekte Sphinx und Julius erfordern einen hohen Einarbeitungsaufwand, da für ein lauffähiges System umfangreicher Konfigurations- und teilweise Programmieraufwand anfällt. Der Autor konnte kein vollständig konfiguriertes Paket für die Verschriftlichung von deutscher Sprache auf Basis dieser Projekte finden. Eine Einarbeitung in diese Projekte lohnt sich jedoch bei ausreichender Projektlaufzeit, da sie weitgehend konfigurierbar und damit flexibler sind als die Alternativen.
Die Speech API von Microsoft (Version 5) ist in jedem Microsoft Windows Betriebssystem ab Windows XP enthalten. Die unterstützte Sprache hängt von der Sprache des Systems ab. Ein englisches Windows unterstützt ein Diktat in englischer Sprache, ein deutsches Windows unterstützt ein Diktat in deutscher Sprache. Das akustische Modell muss sprecherabhängig trainiert werden. Das trainierte Sprecherprofil kann exportiert und auf einer anderen Installation wieder importiert werden. Der Wortschatz ist allgemein gehalten und ausreichend groß. Die Speech API kann sowohl über C++ (MFC) als auch über C# (.NET) angesprochen werden.
Für das Projekt OLL wird Microsoft Speech API (Version 5.4 als Teil von Windows 7) als Spracherkennungssystem gewählt.
Informationen über erkannte Worte
Die Microsoft Speech API gibt bei einem Spracherkennungsprozess nicht nur die erkannten Worte aus, sondern darüber hinaus die folgenden Informationen.
- Anfang und Länge einer erkannten Phrase in Sekunden
- Erkennungssicherheit einer Phrase als Wert zwischen 0 und 1
- Zeichenkette eines Worte
- Lautfolge eines Wortes in der IPA-Notation
- Erkennungssicherheit eines Wortes als Wert zwischen 0 und 1
- Alternative Wortfolgen für eine Phrase
Filterung der Ergebnisse
Anschließend an die Spracherkennung soll die Möglichkeit untersucht werden, relevante Worte aus der Menge der erkannten Worte heraus zu filtern. Die Herausforderung besteht dabei aus zwei Teilen. Zunächst muss eine zielführende Definition für den Begriff relevant gefunden werden. Anschließend müssen Filterkriterien gefunden werden, die mit angemessenem Aufwand relevante Worte von nicht relevanten Worten unterscheidet. Des Weiteren müssen auch Filterkriterien gefunden werden, welche die Erkennungssicherheit der Worte berücksichtigt.
Relevante Worte
Für die Abgrenzung relevanter Worte von nicht relevanten Worten, muss die Zielstellung des Projektes betrachtet werden. Wesentliche Ergebnisse des Prozesses sollen Worthäufigkeitslisten und eine Zuordnung zu Kategorien sein. Da nicht vorgegeben ist, welche Art von Wörtern die Worthäufigkeitslisten enthalten sollen, hilft diese Anforderung nicht bei der Abgrenzung relevanter Wörter. Die Zuordnung zu Kategorien kann jedoch eine Hilfe sein, um eine Abgrenzung zu finden.
In Folge soll der Begriff relevant dahingehend konkretisiert werden, dass ein Wort dann relevant ist, wenn es dabei hilft ein Video zu einer Kategorie zu zuordnen. Damit keine Missverständnisse über den Begriff Kategorie entstehen, muss an dieser Stelle kurz dem weiter unten folgendem Abschnitt Zuordnung von Videos zu Kategorien vorgegriffen werden: Eine Kategorie ist ein Begriff, der durch eine Worthäufigkeitsliste mit anderen Worten in Beziehung gesetzt wird. Der Grad, mit dem ein Text einer Kategorie zugeordnet wird, entspricht der Ähnlichkeit zwischen der Worthäufigkeitsliste des Textes und der Worthäufigkeitsliste der Kategorie.
Die Zuordnung zwischen einem Video und einer Kategorie soll im Idealfall dem Inhalt nach erfolgen und nicht z.B. nach der Anzahl gleicher Artikel oder Hilfsverben. Also muss für die Zuordnung eine Wortart gefunden werden, die einerseits einfach zu identifizieren ist, und andererseits den größten Teil des Inhalts transportiert.
Filterkriterien
Die Filterkriterien bilden sich zum einen aus der Wortrelevanz und zum anderen aus der Erkennungssicherheit.
Relevanz
In der deutschen Sprache erscheinen die Substantive und die Eigennamen als zwei viel versprechende Wortarten, um ein Relevanz-Kriterium zu bilden. Denn einerseits legt die deutsche Sprache einen Großteil der thematischen Bedeutung in diese beiden Wortarten und andererseits können Substantive und Eigennamen durch die Großschreibung leicht von anderen Wortarten unterschieden werden. Dabei sollte jedoch nach Möglichkeit die Grundform eines Wortes verwendet werden und nicht die grammatikalisch transformierte Form, da in der deutschen Sprache alle Wortarten am Anfang eines Satzes großgeschrieben werden.
Um Substantive bei der Zuordnung auszuschließen, die keine besondere thematische Bedeutung tragen, sondern in nahezu allen Texten vorkommen, erscheint es sinnvoll eine Liste mit allgemein häufig auftretenden Worten als Blacklist zu verwenden.
Erkennungssicherheit
Da das ausgewählte Spracherkennungssystem die Erkennungssicherheit für jedes Wort ausgibt, bietet sich diese Größe ebenfalls als Filterkriterium an. Denn Worte die nur mit einer sehr geringen Sicherheit, und damit im Umkehrschluss häufig falsch erkannt wurden, können die Zuordnung zu einer Kategorie störend beeinflussen. Da die Erkennungssicherheit eines erkannten Wortes als Zahl zwischen 0 und 1 gegeben ist, kann ein Schwellwert von z.B. 0,7 als Kriterium verwendet werden.
Zu der Ausgabe des Spracherkennungssystems gehören auch Zahlen, Satzzeichen, Sonderzeichen und Abkürzungen in der Form E. U.. Deshalb wurden Filterkriterien implementiert die Worte mit nicht alphabetischen Zeichen und Worte mit weniger als drei Zeichen ausschließen.
Darstellung der Ergebnisse
In diesem Abschnitt wird beschrieben, welche Erkenntnisse über die Darstellung der Spracherkennungsergebnisse gewonnen wurden. Des Weiteren werden einige Entwurfsentscheidungen für das Projektergebnis dokumentiert.
Präsentationsformat
Es wurde untersucht, mit welchem Ausgabeformat die Ergebnisse der Spracherkennung am besten dargestellt werden können. Dabei wurden die folgenden Formate in Erwägung gezogen.
- Reintext
- XML
- einfaches HTML
- HTML5 mit JavaScript
Bewertungskriterien
- Visuelle Ausdruckskraft
Bewertet wie vielfältig das Layout und die Formatierung gestaltet werden können ist. - Interaktivität
Bewertet wie stark Interaktionen mit dem Benutzer zur Navigation und Anpassung der Darstellung möglich sind. - Multimedia
Bewertet wie gut multimediale Inhalte eingebettet werden können. - Portabilität
Bewertet wie leicht die Ausgabe auf andere Geräte übertragen werden kann. - Maschinenlesbarkeit
Bewertet wie gut die gespeicherten Informationen für eine weitere Verarbeitung durch Scripts genutzt werden können. - Aufwand bei Erstellung
Bewertet den Aufwand der für Umsetzung notwendig ist. (Eine hohe Zahl bedeutet geringen Aufwand, eine niedrige Zahl hohen Aufwand.)
Auswahl
Die Formate werden unter jedem Kriterium bewertet. Die Bewertung erfolgt zwischen 0 und 2.
| Kriterium | Text | XML | HTML | HTML5/JS | |
|---|---|---|---|---|---|
| Visuelle Ausdruckskraft | 0 | 1 | 2 | 2 | 2 |
| Interaktivität | 0 | 0 | 1 | 2 | 1 |
| Multimedia | 0 | 0 | 1 | 2 | 1 |
| Portabilität | 2 | 1 | 2 | 2 | 1 |
| Maschinenlesbarkeit | 2 | 2 | 1 | 1 | 0 |
| Aufwand bei Erstellung | 2 | 2 | 1 | 0 | 0 |
Die Darstellung in Reintext bietet sich für die Ausgabe eines Transkripts für ein einzelnes Video an, ist einfach zu erzeugen, kann jedoch keine zusätzlichen Informationen (wie Erkennungssicherheit) aufnehmen ohne die Darstellung zu stören und bietet keine Multimediaunterstützung (z.B. Einbettung des Quellvideos).
Das XML-Format eignet sich sehr gut, um alle während der Spracherkennung gewonnenen Informationen strukturiert zu speichern. XML-Dateien lassen sich in nahezu allen üblichen Programmiersprachen einfach weiterverarbeiten. XML kann durch ein CSS in begrenztem Maße formatiert und potentiell durch ein XSLT in HTML umgewandelt werden.
Einfaches HTML bietet reichhaltige Möglichkeiten zur Formatierung der Ergebnisse. Es können leicht mehrere Seiten zur Darstellung verwendet werden, die miteinander verknüpft sind. Es eignet sich auch gut für die Verbreitung der Ergebnisse über das Internet. HTML wird auf einer Vielzahl von Geräten unterstützt. Es können ohne Probleme Bilder (z.B. Wortwolken) eingebunden werden, es besitzt jedoch keine gute Unterstützung für Video oder Audio. Der Aufwand für die Erzeugung von HTML hält sich in Grenzen.
Die Version 5 von HTML im Zusammenspiel mit JavaScript erbt die positiven Eigenschaften von HTML und erweitert diese um eine gute Unterstützung für weitgehende Interaktion, Video und Audio. Die einzige Einschränkung ist, dass es einen möglichst aktuellen Browser voraussetzt. Bei der Produktion von interaktiven HTML5-Seiten entsteht durch die zusätzliche JavaScript-Programmierung ein erhöhter Aufwand.
Das Portable Document Format (PDF) von Adobe hat sich in vielen Bereichen für die Weitergabe von Dokumenten durchgesetzt. Seine größte Stärke ist dabei, dass Formatierung und Layout auf jedem unterstützten Gerät weitgehend identisch reproduziert wird. Nachteil dieses Formates ist die mangelnde Unterstützung für Video und Interaktivität. Auch der Aufwand für die Erzeugung eines PDF ist relativ hoch.
Die Ergebnisse des Prozesses im Projekt OLL werden in HTML5 mit JavaScript ausgegeben. Zusätzlich werden die erkannten Worte der Videos als Transkript in Reintext ausgegeben und detaillierte Informationen über die erkannten Worte, einschließlich Erkennungssicherheiten und einer Worthäufigkeitsliste als XML-Datei gespeichert.
Wortwolke
Es wurde untersucht, ob die Anwendung wordizer von APP Helmond durch Scripts angesteuert und so, zur Erzeugung von Wortwolken, in den automatisierten Prozess eingebunden werden kann.
Um die Wortwolke in eine interaktive Oberfläche einbinden zu können wurde eine Anforderung ergänzt, die in der Zielstellung nicht aufgeführt ist: Die Anwendung zur Erzeugung der Wortwolke muss neben der bildlichen Darstellung der Wortwolke auch die Positionen und Flächen der Worte in der Wortwolke als Datensatz ausgeben. Nur dadurch wird es möglich, die Worte der Wortwolke als aktive Links zu gestalten und damit zur Navigation zu den entsprechenden Details zu nutzen.
Das Ergebnis der Untersuchung ergab, dass wordizer weder mit angemessenem Aufwand durch Scripts angesteuert werden kann, noch die Möglichkeit bietet, die Wortpositionen und -flächen auszugeben. In Folge wurde nach weiteren Anwendungen recherchiert, die Wortwolken erzeugen können. Keine der gefundenen Anwendungen bot die Möglichkeit die Wortpositionen und -flächen auszugeben.
Aus diesem Grund wurde eine neue Programmbibliothek (mastersign.cloud) zur Erzeugung von Wortwolken implementiert, welche die gestellten Anforderungen erfüllt. Als Grundlage wurde der von Jonathan Feinberg – Entwickler von Wordle – auf stackoverflow veröffentlichte Algorithmus verwendet. Als technische Plattform diente die Java Laufzeitumgebung und die Programmiersprache Clojure.
Die erzeugten Wortwolken können zwei Größen visualisieren:
- die Häufigkeit eines Wortes wird durch die Schriftgröße dargestellt
- die Sicherheit mit der ein Wort durchschnittlich erkannt wurde wird durch die Schriftfarbe dargestellt
Für die möglichen Ausrichtungen der Worte wurde horizontal, vertikal links gedreht und vertikal rechts gedreht gewählt. Bei der Verwendung dieser Ausrichtungen kann eine gute Lesbarkeit und gleichzeitig eine hohe Ausnutzung des verfügbaren Platzes erreicht werden (siehe Abbildung 1).

Als Weiterentwicklung der bekannten Wortwolkenformen wurde der Algorithmus dahingehend modifiziert, dass Worte wenn möglich alphabetisch sortiert platziert werden (siehe Abbildung 2). Worte mit den Anfangsbuchstaben A bis N werden tendenziell in der oberen Hälfte der Wortwolke von links nach rechts positioniert. Worte mit den Anfangsbuchstaben O-Z werden tendenziell in der unteren Hälfte von links nach rechts positioniert. Diese Form der Sortierung ermöglicht möglicherweise intuitiv das schnelle Auffinden eines bekannten Wortes in der Wortwolke.

Glossar
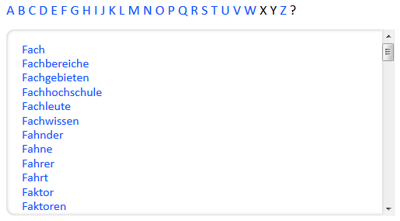
Gemäß der Zielstellung wurde untersucht, in welcher Form die erkannten Worte durch ein Glossar zugänglich gemacht werden können.
In der HTML5-Ausgabe des Prozesses werden für jedes Video ein individueller Glossar und für alle Videos ein gemeinsamer Glossar erzeugt (siehe Abbildung 3). Der Glossar erlaubt die Navigation zwischen den Buchstaben des Alphabets.
Transkript und Video
Des Weiteren wurde untersucht wie das Transkript eines Videos dargestellt werden kann und ob eine Navigation von erkannten Worten zu den Positionen im Video möglich ist, an denen das Wort auftritt.
Durch die Unterstützung von HTML5 für eingebettetes Video ist es möglich das Video gemeinsam mit dem Transkript in einer Seite darzustellen. Da der Video-Player in einem HTML5-fähigen Browser eine Steuerung durch JavaScript unterstützt ist es auch möglich automatisch an bestimmte Positionen in einem Video zu springen und das Video ab dieser Position abzuspielen.
Das Transkript wird in einem Bereich unter dem Video angezeigt (siehe Abbildung 4). Es besteht aus einer Liste mit Phrasen. Vor jeder Phrase steht die Position der Phrase im Video. Durch einen Klick auf die Uhrzeit springt der Video-Player an die entsprechende Position und startet die Wiedergabe. Die Worte der Phrasen werden farblich abgestuft dargestellt. Worte mit kräftiger Farbe wurden mit hoher Sicherheit erkannt, Worte mit schwacher Farbe wurden mit geringer Sicherheit erkannt. Ein Klick auf ein Wort leitet zu einer Detailseite für das jeweilige Wort (siehe Abbildung 5).


Zuordnung von Videos zu Kategorien
Eine Kategorie wird durch eine Worthäufigkeitsliste definiert. Die Worthäufigkeitsliste für eine Kategorie kann aus einem oder mehreren Texten, die aneinander gehängt werden, gewonnen werden. In dem in diesem Projekt implementierten Prozess können Reintexte, HTML-Seiten und mit besonderer Berücksichtigung MediaWiki-Seiten verwendet werden. Die Texte werden durch einen URL referenziert und können somit sowohl lokal, als auch im Internet gespeichert sein.
Die besondere Berücksichtigung von MediaWiki-Seiten wurde implementiert, um die Definition einer Kategorie durch Wikipedia-Seiten zu erleichtern. Durch das Vorwissen über den Aufbau von MediaWiki-Seiten ist es möglich Wiki-spezifische Worte und HTML-Element vor der weiteren Verarbeitung heraus zu filtern.
Da der Zweck der Worthäufigkeitsliste einer Kategorie darin besteht mit der Worthäufigkeitsliste eines Videos verglichen zu werden, können die Texte einer Kategorie mit den gleichen Kriterien gefiltert werden wie die erkannten Worte eines Videos. Mit dem Unterschied dass die Worte in den Texten einer Kategorie keine Erkennungssicherheit besitzen und deshalb eine Erkennungssicherheit von 1 angenommen werden muss.
Der eigentliche Zuordnungsprozess erfolgt durch die Multiplikation der Häufigkeit eines Wortes aus dem Video mit der Häufigkeit des gleichen Wortes aus der Kategorie und die Summierung der multiplizierten Worthäufigkeiten. Kommt ein Wort nur in einer der beiden Worthäufigkeitslisten vor, wird es nicht berücksichtigt.
Da die Anzahl der erkannten Worte in einem Video und die Anzahl der Worte in den Texten einer Kategorie variieren kann, müssen die Worthäufigkeiten vor der Multiplikation normiert werden. Das geschieht mittels der Division durch die größte Worthäufigkeit der jeweiligen Worthäufigkeitsliste. Im Ergebnis kann eine multiplizierte Worthäufigkeit den Wert 1 nicht überschreiten. Und die Summe der multiplizierten Worthäufigkeiten kann die Anzahl der Worte nicht überschreiten, die sowohl im Video als auch in der Kategorie vorkommen. Dieser Wert wird in den Prozessergebnissen als Übereinstimmung bezeichnet.
Werden m Videos n Kategorien zugeordnet, wird die Übereinstimmung m x n mal berechnet. Diese Übereinstimmungen werden in der Prozessausgabe als Matrix dargestellt (siehe Abbildung 6).
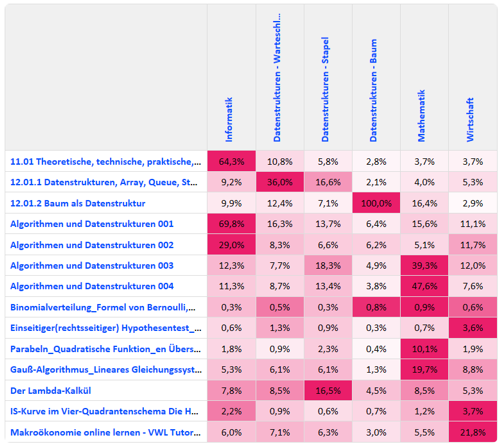
Die Hintergrundfarben der Zellen in der Übereinstimmungsmatrix geben die Übereinstimmung relativ zur besten Übereinstimmung für das jeweilige Video an. Die Prozentzahl in den Zellen gibt die Übereinstimmung relativ zur besten Übereinstimmung für alle Videos an.
Erkenntnisse
Aus den theoretischen Betrachtungen und den praktischen Erfahrungen im Umgang mit dem implementierten Prozess konnten die folgenden Erkenntnisse gewonnen werden.
Qualitätsfaktoren
Die Erkennungsleistung des Spracherkennungssystems hängt von einer Vielzahl von Faktoren ab, die bei der Einschätzung der Prozessergebnisse berücksichtigt werden müssen.
Technische Faktoren
- Mikrofon
Die Eigenschaften des Mikrofons (Dynamik, Aufnahmecharakteristik, Empfindlichkeit für Erschütterungen und Pop-Geräusche) beeinflussen maßgeblich die Qualität des aufgenommenen Audiosignals und damit die Erkennungsleistung.
Die besten Ergebnisse können mit hochwertigen Headset- oder Lavelier-Mikrofonen erreicht werden. - Umgebungsgeräusche
Werden neben dem Sprecher Umgebungsgeräusche aufgezeichnet, können diese zu falsch erkannten Wörtern führen. Ein Spracherkennungssystem besitzt in der Regel eine Filterstufe, die versucht Geräusche von vokalen Lauten zu unterscheiden. - Abstand des Sprechers zum Mikrofon
Der Abstand zwischen dem Mund des Sprechers und dem Mikrofon ist je nach Mikrofon mehr oder weniger wichtig für ein ausreichend kräftiges Audio-Signal. Ist der Abstand groß sind Umgebungsgeräusche relativ zum Sprecher lauter. Ist der Abstand zu gering treten häufiger Pop-Geräusche oder sogar Geräusche durch die Berührung zwischen Mund und Mikrofon auf. Ein Spracherkennungssystem versucht in der Regel den charakteristischen Klang einer Sprecher-Mikrofon-Kombination in der Trainingsphase des akustischen Modells zu berücksichtigen bzw. kennen zu lernen. - Kompressionsartefakte Die meisten Tonspuren in Videos werden mit einem verlustbehafteten Kompressionsverfahren kodiert. Diese Art der Kodierung erzeugt eine mehr oder weniger starke Verzerrung des Tonsignals, die bei stärkerer Kompression auch zu hörbaren Artefakten führt. Die gängigen Kompressionsverfahren versuchen dabei, gemäß eines psychoakustischen Modells die Frequenzanteile, die für das menschliche Hören wichtig sind, so wenig wie möglich zu verzerren.
Dieser Faktor wird im Abschnitt Kompressionsartefakte noch genauer untersucht.
Menschliche Faktoren
- Dialekt, Akzent
Der deutsche Wortschatz eines Spracherkennungssystems berücksichtigt i.d.R. nur die Standardsprache mit ihrer relativ gut definierten Aussprache und den dadurch gegebenen Lautfolgen. Benutzt der Sprecher einen Dialekt oder spricht er mit Akzent, passt seine Aussprache weniger zu den Lautfolgen die im Wortschatz hinterlegt sind. Daraus resultiert eine zum Teil drastisch verschlechterte Erkennungsleistung. - Deutlichkeit der Aussprache
Spricht der Sprecher undeutlich, nimmt die Erkennungsleistung des Systems ab. - Geschwindigkeit der Aussprache
Spricht ein Sprecher sehr schnell oder sehr langsam, kann das Spracherkennungssystem die Grenzen der einzelnen Laute und Worte nicht mehr sauber erkennen und die Erkennungsleistung nimmt ab.
Systemfaktoren
- Training des akustischen Modells (Sprecherprofile)
Ein für dieses Projekt besonders wichtiger Faktor ist das Training des akustischen Modells. Dieser Faktor wird im Abschnitt Sprecherprofile noch genauer untersucht. - Abdeckung des Wortschatzes
Wird der Wortschatz des Sprechers nur unzureichend vom Wortschatz des Systems abgedeckt, können nur die allgemeineren Worte aus der deutschen Kernsprache erkannt werden. Das führt zum einen zu einer allgemein schlechteren Erkennungsleistung. Zum anderen führt es aber auch dazu, dass insbesondere jene Worte denen die größte inhaltliche Bedeutung zukommt und damit die größte Relevanz besitzen, nicht für die Zuordnung eines Video zu einer Kategorie zur Verfügung stehen. - Anzahl der Worte in einer Aufnahme
Die Anzahl der Worte in der Aufnahme, verändert nicht die Erkennungsleistung des Spracherkennungssystems, da die Microsoft Speech API jede Phrase individuell analysiert. Dabei kommen keine adaptiven Verfahren zum Einsatz, die die Erkennungsleistung in Abhängigkeit der bereits erkannten vorhergehenden Worte beeinflusst. Bei anderen Spracherkennungssystem kann das anders sein. Die Qualität der Zuordnung eines Videos zu einer Kategorie wird jedoch sehr wohl durch die Anzahl der Worte in einer Aufnahme beeinflusst. Denn die Worthäufigkeiten und die daraus errechnete Übereinstimmung sind umso aussagekräftiger, je mehr Worte dabei berücksichtigt wurden. - Anzahl der Worte einer Kategorie
Für die Anzahl der Worte in einer Kategorie gibt es vermutlich ein jedoch in diesem Projekt nicht näher untersuchtes Optimum. Denn wenn eine Kategorie durch zu wenige Worte beschrieben wird, steigt die Wahrscheinlichkeit, dass in einem Video andere Worte verwendet wurden, um über das gleiche Thema zu sprechen. Wenn jedoch eine Kategorie durch zu viele Worte beschrieben wird, sinkt die Trennschärfe zwischen mehreren Kategorien und die Aussagekraft der Zuordnung sinkt.
Kompressionsartefakte
Um die Abhängigkeit der Erkennungsleistung von der Kompressionsrate der Tonspur zu untersuchen, wurde das folgende Experiment durchgeführt. Es wurde ein Profil trainiert und durch den gleichen Sprecher, mit dem gleichen Mikrofon und bei vergleichbaren Umgebungsgeräuschen ein bekannter Text vorgelesen und aufgenommen. Als Mikrofon kam ein Headset der Firma Logitech mit integrierter USB-Soundkarte zum Einsatz. Die Speicherung der Aufnahme erfolgte im nicht komprimierenden PCM-Wave-Format bei einer Auflösung von 16 Bit und einer Abtastrate von 44,1 kHz.
Diese Datei wurde mit Hilfe von FFmpeg zunächst in verschiedene Auflösungen (16 und 8 Bit) und Abtastraten umgerechnet (44.100, 32.000, 22.050, 16.000, 11.025, 8.000 Hz). Des Weiteren wurde die Originaldatei mit Hilfe des MP3-Lame-Encoders (Version 3.99.5) und des experimentellen AAC-Encoders von FFmpeg (Version N-58699-ge3d7a39 vom 01.12.2013) für verschiedene konstante Bit-Raten komprimiert (128, 96, 64, 48, 32, 24, 16, 8 kBit/s).
Die Originaldatei und die verschiedenartig kodierten abgeleiteten Varianten wurden anschließend mit der Microsoft Speech API verarbeitet. Die Erkennungsergebnisse geben über die Abhängigkeit der Erkennungsleistung von der Qualität des Ausgangsmaterials Auskunft.
Auflösung und Abtastrate
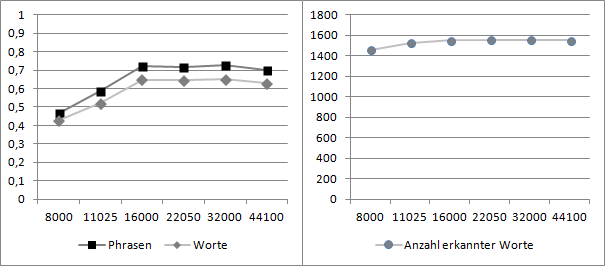
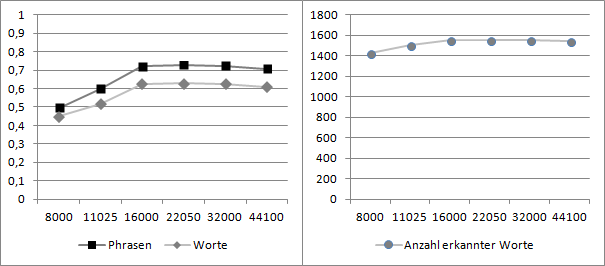
Wie in Abbildung 7 und Abbildung 8 zu erkennen ist, ist die Erkennungsleistung der Bei 16- und 8-Bit-Auflösung sehr ähnlich, was darauf schließen lässt, dass die Spracherkennung für 8-Bit-Auflösung optimiert ist und von einer höheren Auflösung nicht profitieren kann.
Des Weiteren ist die Erkennungsleistung bei 44.100, 32.000, 22.050 und 16.000 Hz nahezu identisch mit einer geringfügig schwächeren Leistung bei der Original-Abtastrate von 44.100 Hz. Bei reduzierten Abtastraten von 11.025 und 8.000 Hz bricht die Erkennungsleistung deutlich ein. Wodurch die leicht erhöhte Erkennungsleitung zustande kommt, wenn Ausgangsmaterial von 44.100 Hz auf 16.000 - 32.000 Hz herunter gerechnet wird konnte im Projekt nicht eindeutig geklärt werden. Es lässt sich vermuten, dass durch die Reduzierung der Bandbreite ein Glättungseffekt erzielt wird, der den Rauschanteil im Signal senkt.
Im Hinblick auf eine effiziente Speichernutzung für Audiodaten lässt sich sagen, dass für die Microsoft Speech API eine 8-Bit-Kodierung und eine Abtastrate von 16.000 Hz ausreicht, da das Spracherkennungssystem von höherer Auflösung oder Abtastrate nicht profitieren kann.
Verlustbehaftete Kompression
Besonders interessant für das Projekt ist die Auswirkung einer verlustbehafteten Kompression des Audiosignals auf die Spracherkennungsleistung, da eine Tonspur in den gängigen Videoformaten in dieser Weise gespeichert wird. Hier wurde die Auswirkung der MP3- und der AAC-Kompression untersucht. In Abbildung 9 ist zu erkennen, dass die Erkennungsleistung für MP3 von 128 bis 48 kBit/s relativ stabil bleibt und unterhalb von 48 kBit/s deutlich abfällt. Die Erkennungsleistung von AAC (vergl. Abbildung 10) verhält sich ebenfalls bis 48 kBit/s stabil und liegt etwas über der von MP3. Unterhalb von 48 kBit/s fällt die Erkennungsleistung noch schneller ab als bei MP3.
Die schlechte Erkennungsleistung bei der AAC-Kompression mit niedrigen Bitraten ist eventuell auf den experimentellen AAC-Codec von FFmpeg zurück zu führen. FFmpeg unterstützt in der verwendeten Version mehrere Encoder-Bibliotheken für AAC: libvo_aacenc, aac, libfaac und libfdk_aac. In der Dokumentation werden diese Encoder in der hier aufgeführten Reihenfolge der Kodierungsqualität nach geordnet. Wobei libvo_aacenc die schlechteste und libfdk_aac die beste Qualität produziert. Da die Binärpakete für FFmpeg aus lizenztechnischen Gründen nur libvo_aacenc und aac enthalten, wurde für diese Experimente die noch als experimentell eingestufte eingebaute Bibliothek aac verwendet. In der Dokumentation wird jedoch auf Grund des deutlichen Qualitätsunterschieds die Verwendung der Bibliothek libfdk_aac empfohlen, welche am Frauenhofer Institut entwickelt wird.
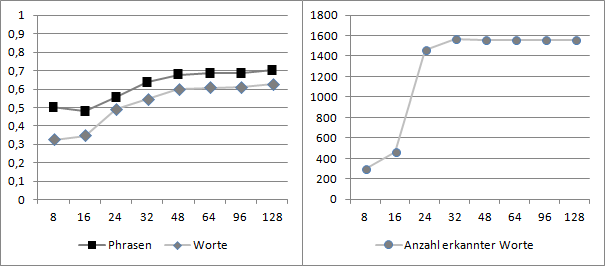
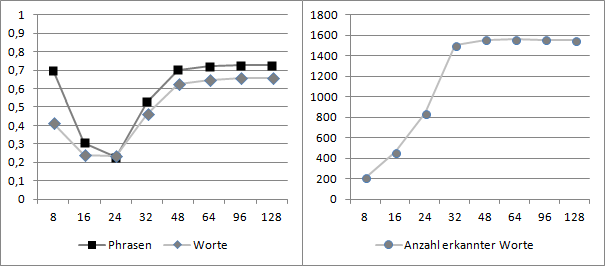
Zu beachten ist, dass die Bitraten für eine Mono-Tonspur angegeben sind.
Sprecherprofile
Die Microsoft Speech API arbeitet mit einem statischen akustischen Modell als Teil des Sprecherprofils. Das bedeutet, dass das Modell einmal trainiert wird und anschließend nur durch Benutzerinteraktion (Angabe von Korrekturen im Diktat) weiter trainiert werden kann. Wurde das akustische Modell von dem gleichen Sprecher mit dem gleichen Mikrofon bei wenigen Umgebungsgeräuschen trainiert wie bei der Tonaufnahme für die Verschriftlichung, sind die Ergebnisse auch als Transkript brauchbar.
Weicht jedoch die Aussprache des Sprechers bei der Tonaufnahme für die Verschriftlichung von der des Sprechers, welcher das akustische Modell trainiert hat, ab, sinkt die Erkennungsleistung des Systems deutlich.
Da in diesem Projekt die Microsoft Speech API verwendet wird, und auch keine interaktiven Korrekturen während der Verschriftlichung möglich sind, steht nur ein statisches akustisches Modell für die Erkennung zur Verfügung. Aus diesem Grund wurde der Prozess derart implementiert, dass mehrere Sprecherprofile installiert werden können. Aus diesen wählt dass System für jedes Video jenes Profil aus, das für eine benutzerdefinierte Zeitspanne aus dem Anfang des Video die beste Erkennungsleistung erbringt.
Um die Erkennungsleistung der Microsoft Speech API bei der Verwendung von Sprecherprofilen zu testen, die von einem anderen Sprecher trainiert wurden als dem, der die zu erkennende Tonspur gesprochen hat, wurde das folgende Experiment durchgeführt.
Es wurden zwei Videos (1 und 2) mit einer aufgezeichneten Lehrveranstaltung mit jeweils drei Profilen (A, B, und C) verarbeitet, die von unterschiedlichen Sprechern trainiert wurden. Es kamen folglich 5 Sprecher zum Einsatz. Zwei für die Videos und zwei weitere für die Profile.
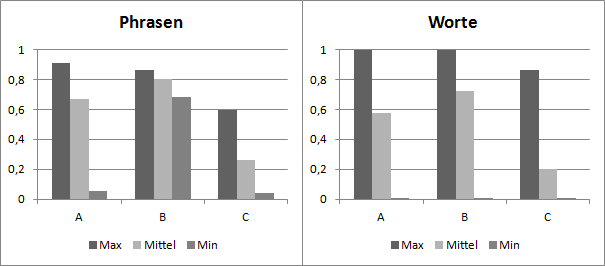
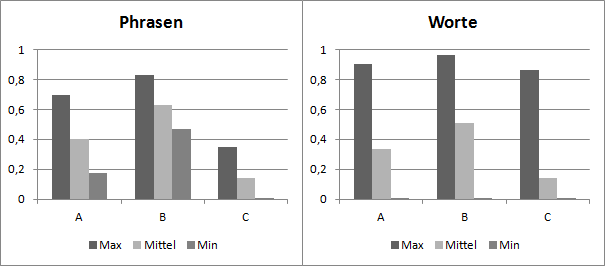
Wie in Abbildung 11 und Abbildung 12 erkennbar ist, passt Profil B sowohl am besten zu Video 1 als auch zu Video 2. Zu dem Profil B ist der Unterschied nicht so groß wie zu dem Profil C, welches mit beiden Videos zu sehr schlechter Erkennungsleistung führt. Interessant ist die Erkennungssicherheit von Phrasen im Video 1. Die für das Profil A sehr wechselhaft ausfällt, wie an Minimum und Maximum abzulesen ist, für Profil B jedoch deutlich stabiler ist.
Laufzeitverhalten
Die folgenden Größen sind für das Laufzeitverhalten des in diesem Projekt implementierten Prozesses ausschlaggebend:
Eingabedaten
- Anzahl der Videos
- Länge aller Videos
- Anzahl der Kategorien
- Anzahl aller Worte in den Kategorien
System
- Anzahl der installierten Sprecherprofile
- Anzahl der Prozessorkerne
Die folgenden Vorgänge benötigen die meiste Zeit:
- Extraktion der Tonspur (parallel)
- Ermitteln des optimalen Sprecherprofils für jede Tonspur (zu jedem Zeitpunkt immer nur ein Sprecherprofil, aber mehrere Tonspuren parallel)
- Spracherkennung für die kompletten Tonspuren (zu jedem Zeitpunkt immer nur ein Sprecherprofil, aber mehrere Tonspuren parallel)
- Erzeugen der Wortwolken (parallel)
Daraus ergibt sich, dass die Laufzeit in der Größenordnung mit erhöhter Anzahl von Videos und erhöhter Anzahl von alternativen Sprecherprofilen im Quadrat steigt.
Sollte es hypothetisch erforderlich sein Tonspuren in anderen Sprachen zu verarbeiten, gilt die Einschränkung, dass für jede Sprache eine eigene Windows Installation in der jeweiligen Sprache erforderlich ist. Dieser Fall wird aber von dem in diesem Projekt implementierten Prozess nicht abgedeckt. ffmpeg
Fazit und Ausblick
In diesem Projekt wurde die Software FFmpeg für die Extraktion einer Tonspur aus einem Video gefunden und getestet. Diese Software wird über die Befehlszeile gesteuert und kann somit leicht in einen automatisierten Prozess eingebunden werden. FFmpeg unterstützt eine Vielzahl der gängigen Video- und Audio-Formate sowohl als Eingabe als auch als Ausgabe.
Es wurden verschiedene Spracherkennungssystem anhand der folgenden Kriterien verglichen: geringer Einarbeitungsaufwand, Verfügbarkeit aller Bausteine für die Spracherkennung, Erfüllung aller technischen Voraussetzungen, geringe Kosten, Transparenz und Flexibilität.
Entsprechend den Anforderungen und Rahmenbedingungen dieses Projektes wurde die Microsoft Speech API (Teil des Microsoft Windows 7 Betriebssystems) als Spracherkennungssystem gewählt. Es lässt sich über eine gut dokumentierte Schnittstelle mit eine Programmiersprache ansteuern, und es gibt eine Reihe von wichtigen Details über die erkannten Worte und Phrasen aus (z.B. Position, Erkennungssicherheit). Es unterstützt die Spracherkennung nur mit Hilfe von trainierten Profilen. Wenn jedoch eine Anzahl von unterschiedlichen Profilen für die Erkennung verwendet wird und die besten Ergebnisse ausgewählt werden, ist die Erkennungsleistung für eine thematische Zuordnung eines Videos ausreichend. Ein ausreichend sauberer Volltext kann jedoch bei Videomaterial mit unbekannten Sprechern nicht erzielt werden. Es bleibt zu prüfen, ob eines der anderen kommerziellen Systeme (z.B. Voice Pro von Linguatec) eine bessere Erkennungsleistung mit unbekannten Sprechern erzielt.
Es wurden verschiedene Filter implementiert, um die erkannten Worte zu filtern. Dabei werden sowohl die Erkennungssicherheit berücksichtigt, als auch lexikalische Eigenschaften wie Wortlänge und Großschreibung. Darüber hinaus ist die Verwendung einer Blacklist möglich. Die Blacklist ist zurzeit auf eine Liste mit den häufigsten kleingeschriebenen Worten der deutschen Sprache festgelegt. In Zukunft könnte die Auswahl und oder Erzeugung einer variablen Blacklist implementiert werden. Die einzelnen Filter können bei Bedarf parametrisiert und wahlweise aktiviert oder deaktiviert werden.
Für die Ausgabe der Ergebnisse wurden die Formate HTML5, XML und Reintext gewählt. Dadurch ist sowohl eine visuell ansprechende Darstellung der Ergebnisse auf einer Vielzahl von Geräten (Desktop, Tablet, Smartphone) möglich, als auch die weitere maschinelle Verarbeitung der Ergebnisse.
Zur Visualisierung der Worthäufigkeiten in Form einer Wortwolke wurde eine neue Programmbibliothek implementiert, welche die Positionen und Flächen der Worte in der Wolke ausgibt und somit die Verlinkung der Worte in der Wolke mit dem Glossar und dem Transkript ermöglicht.
Da die Microsoft Speech API zu jeder erkannten Phrase die Position in der Tonspur angibt und HTML5 einen Video-Player unterstützt, war es möglich die erkannten Worte mit der Abspielposition des Videos zu verknüpfen. Es kann aus dem Glossar und aus einer Wortwolke zu den Positionen im Video navigiert werden, an denen das jeweilige Wort erkannt wurde.
Für die Zuordnung der Videos zu einer Anzahl von benutzerdefinierten Kategorien wurde eine Kennzahl definiert, mit der die Übereinstimmung zwischen einem Video und einer Kategorie berechnet werden kann. Dazu wird sowohl für das Video als auch für die Kategorie eine Worthäufigkeitsliste erzeugt. Eine Kategorie kann durch eine Menge von Quelltexten beschrieben werden. Als Quelltexte können sowohl lokale Textdateien als auch gewöhnliche Webseiten und insbesondere Wikipedia-Seiten verwendet werden.
Für die Steuerung des automatisierten Prozesses wurde eine grafische Benutzeroberfläche implementiert, welche die Verwaltung der Videos, der Kategorien und der Prozessparameter ermöglicht. Während der Ausführung des Prozesses, die bei einer größeren Anzahl von Videos und Sprecherprofilen mehrere Stunden in Anspruch nehmen kann, werden die einzelnen Prozessschritte und deren Fortschritt übersichtlich dargestellt. Des Weiteren werden alle Schritte in einer Protokolldatei dokumentiert. Es gibt die Möglichkeit Zwischenergebnisse des Prozesses aufzuheben und somit eine wiederholte Ausführung mit veränderter Parametrisierung wesentlich zu Beschleunigen.
Die in diesem Projekt entstandene Software wurde unter dem Namen MediaCategorizer auf der Plattform github unter der MIT-Lizenz veröffentlicht.
Anhang
Die folgenden Dokumente gehören ebenfalls zum Projektergebnis.
- MediaCategorizer - Benutzerhandbuch
- MediaCategorizer - Sprecherprofile
- MediaCategorizer - Systemarchitektur
- MediaCategorizer - Struktur der Ergebniswebseite
- MediaCategorizer - Intermediate Data Structures (englisch)
Quellen
Die folgenden Quellen wurden verwendet.
Bellegarda, J.R. 2000. “Exploiting Latent Semantic Information in Statistical Language Modeling.” Proceedings of the IEEE 88 (8): 1279–1296. doi:10.1109/5.880084.
Lee, Li, and R. Rose. 1998. “A Frequency Warping Approach to Speaker Normalization.” Speech and Audio Processing, IEEE Transactions on 6 (1): 49–60. doi:10.1109/89.650310.
Levinson, S., M.Y. Liberman, A. Ljolje, and L.G. Miller. 1989. “Speaker Independent Phonetic Transcription of Fluent Speech for Large Vocabulary Speech Recognition.” In Acoustics, Speech, and Signal Processing, 1989. ICASSP-89., 1989 International Conference on, 441–444 vol.1. doi:10.1109/ICASSP.1989.266458.
Saon, G., and Jen-Tzung Chien. 2012. “Large-vocabulary Continuous Speech Recognition Systems: a Look at Some Recent Advances.” Signal Processing Magazine, IEEE 29 (6): 18–33. doi:10.1109/MSP.2012.2197156.
Saon, George, and Mukund Padmanabhan. 1999. “Data-driven Approach to Designing Compound Words for Continuous Speech Recognition.” In IEEE Trans. Speech and Audio Processing, 327–332.
Thelen, E. 1996. “Long Term On-line Speaker Adaptation for Large Vocabulary Dictation.” In Spoken Language, 1996. ICSLP 96. Proceedings., Fourth International Conference on, 4:2139–2142 vol.4. doi:10.1109/ICSLP.1996.607226.
Wang, Xuerui, Andrew McCallum, and Xing Wei. 2007. “Topical N-grams: Phrase and Topic Discovery, with an Application to Information Retrieval.” In Proceedings of the 2007 Seventh IEEE International Conference on Data Mining, 697–702. ICDM ’07. Washington, DC, USA: IEEE Computer Society. doi:10.1109/ICDM.2007.86. http://dx.doi.org/10.1109/ICDM.2007.86.
Wegmann, S., D. McAllaster, J. Orloff, and B. Peskin. 1996. “Speaker Normalization on Conversational Telephone Speech.” In Acoustics, Speech, and Signal Processing, 1996. ICASSP-96. Conference Proceedings., 1996 IEEE International Conference on, 1:339–341 vol. 1. doi:10.1109/ICASSP.1996.541101.