MediaCategorizer
Systemarchitektur
Dieses Dokument beschreibt die Architektur und Implementierung von MediaCategorizer. Es soll Softwareentwicklern helfen die Software zu verstehen und somit eine Anpassung und Erweiterung unterstützen.
Übersicht
Das Projekt setzt sich aus den folgenden Komponenten zusammen (siehe Abbildung 1).
- Hauptprojekt MediaCategorizer
- Benutzeroberfläche MediaCategorizer - UI
- Spracherkennung MediaCategorizer - Transcripter
- Analyse und Visualisierung MediaCategorizer - Distillery
- Wortwolkengenerierung Mastersign Cloud
- Medieninspektion FFprobe (extern)
- Tonspurextraktion FFmpeg (extern)
- Wellenformvisualisierung WaveViz (extern)
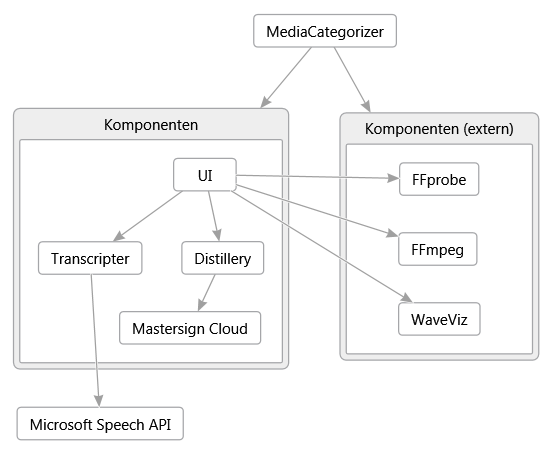
Das Hauptprojekt dient als Startpunkt. Es enthält die Dokumentation und eine Anzahl von Scripts zur Automatisierung des Projektes. Durch die Automatisierung werden die folgenden Aktionen unterstützt:
- Download der externen Komponenten FFmpeg, FFprobe und WaveViz
- Erzeugen der Dokumentation im HTML- und DOCX-Format aus den Markdown-Quelldateien
- Klonen der Komponenten-Repositories UI, Transcripter und Distillery
- Kompilieren der Komponenten
- Zusammenstellen eines lauffähigen Programmpakets
Die Benutzeroberfläche ermöglicht das benutzerfreundliche Verwalten von Projekten (Medien, Kategorien, Parameter). Sie ist für die Koordination der Prozessausführung verantwortlich und nutzt die übrigen Komponenten über deren Befehlszeilenschnittstelle.
Die Tonspurextraktion löst aus den Medien die Tonspur heraus und konvertiert sie in ein Format, das von der Komponente zur Wellenformvisualisierung und der Komponente zur Spracherkennung unterstützt wird.
Die Wellenformvisualisierung erzeugt aus der extrahierten Tonspur eine bildliche Darstellung des Tonsignals. Dieses wird in der HTML5-Ausgabe eingebunden und dient der Veranschaulichung der Dynamik des Tonsignals.
Die Spracherkennung steuert die Microsoft Speech API an und speichert die Spracherkennungsergebnisse als Zwischenergebnis in einer EDN-Datei, welche von der Komponente für Analyse und Visualisierung gelesen werden kann.
Die Komponente für Analyse und Visualisierung filtert zunächst die erkannten Worte und bildet anschließend für Medien und Kategorien Worthäufigkeitslisten. Diese werden in Form von Wortwolken visualisiert. Aus den Worthäufigkeitslisten von Medien und Kategorien werden die Übereinstimmungen zwischen Medien und Kategorien berechnet. Aus den Übereinstimmungen werden dann Zuordnungen zwischen Medien und Kategorien abgeleitet. Die Ergebnisse (einschließlich der erkannten Worte mit ihren Erkennungssicherheiten) werden in Form einer XML-Datei gespeichert. Zusätzlich werden die Volltexte der einzelnen Medien als Reintext gespeichert. Abschließend wird eine statische HTML5-Webseite generiert welche alle Ergebnisse visuell aufbereitet darstellt, die Original-Mediendateien einbindet und eine interaktive Navigation zwischen den Analyseergebnissen erlaubt. Diese Webseite kann sowohl lokal gespeichert und direkt mit einem Browser betrachtet werden, sie kann aber auch mit Hilfe eines Webservers gehostet und so über das Internet verfügbar gemacht werden.
Entwicklungsumgebung
MediaCategorizer wurde mit C# in Visual Studio 2013 und Clojure in LightTable 0.5 implementiert. Deshalb benötigt das Projekt sowohl die Microsoft .NET Laufzeitumgebung als auch die Java Laufzeitumgebung. C# wurden gewählt, weil es mit der WPF-Bibliothek eine schnelle Entwicklung der Benutzeroberfläche und durch die .NET-Schnittstelle eine einfache Anbindung an die Microsoft Speech API ermöglicht. Clojure wurde gewählt, weil das funktionale Programmierparadigma, die komfortablen Bibliotheken für Webseitenerzeugung und die interaktive Entwicklungsumgebung (REPL) eine schnelle Umsetzung der Analyse und Visualisierung ermöglichen. Für die Projektautomatisierung wird die Microsoft PowerShell eingesetzt.
Voraussetzungen
- Microsoft Windows 7 Professional/Enterprise mit Service Pack 1 oder höher
- Git
- Microsoft PowerShell 3 oder höher (in Windows 8 bereits enthalten)
- pandoc 1.12 oder höher
(für das Generieren der Dokumentation aus den Markdown-Quellen erforderlich) - Microsoft .NET Framework 4.5 oder höher (in Windows 8 bereits enthalten)
- Microsoft Visual Studio 2012 oder höher
(für die Anpassung oder Weiterentwicklung von MediaCategorizer oder Transcripter erforderlich) - Java Development Kit 7 oder höher
Komponenten
In den folgenden Abschnitten werden die einzelnen Komponenten detailliert beschrieben.
Hauptprojekt
Projektname: MediaCategorizer
Repository: https://github.com/mastersign/mediacategorizer/
Verzeichnis: /
Merkmale
- Einstiegspunkt
- Dokumentation
- Skripte für das Bauen des Projektes
Setup
Installieren der Voraussetzungen
Für das Kompilieren der Komponenten müssen mindestens .NET 4.5, JDK 7 und PowerShell 3 installiert sein. Für das Erzeugen der Projektdokumentation in HTML und DOCX müssen mindestens PowerShell 3 und pandoc installiert sein.
Klonen des Hauptprojektes in ein lokales Repository
Befehlszeile mit git in
PATHöffnen und> git clone https://github.com/mastersign/mediacategorizer.git D:\MediaCategorizerausführen. Der PfadD:\MediaCategorizerkann bei Bedarf angepasst werden.Erzeugen der Projektdokumentation in HTML und DOCX
In das Verzeichnis
autowechseln und die Windows-Batch-Dateitransform-all-documents.batausführen. Der Vorgang wird in der Dateitransform-all-documents.logprotokolliert.War die Ausführung des Skripts erfolgreich, wurden für jede Markdown-Datei aus dem Verzeichnis
docsje eine HTML-Datei und eine DOCX-Datei im Verzeichnisdocs\outerzeugt. Für die HTML-Dateien wurde zusätzlich das Verzeichnisdocs\imagesnachdocs\out\imageskopiert.Herunterladen der externen Programme, klonen der Komponenten-Repositories, bauen der Komponenten
In das Verzeichnis
autowechseln und die Windows-Batch-Dateiupdate-build-release.batausführen. Der Vorgang wird in der Dateiupdate-build-release.logprotokolliert.Die einzelnen Schritte
Update-Tools.ps1,Update-Components.ps1,Build-Project.ps1undCreate-Release.sp1können auch einzeln ausgeführt werden. Es muss aber berücksichtigt werden, dass die Ausführungsrichtlinie der PowerShell vonRestrictedaufRemoteSignedoderUnrestrictedgesetzt werden muss. Dazu muss die PowerShell mit Administrationsrechten gestartet werden und der Befehl> Set-ExecutionPolicy RemoteSigned -Forceausgeführt werden.War die Ausführung des Skripts erfolgreich, wurde im Verzeichnis
releaseein vollständiges Paket mit MediaCategorizer und allen erforderlichen Abhängigkeiten zusammengestellt.Um MediaCategorizer in Betrieb zu nehmen sind die Anweisungen im Benutzerhandbuch Abschnitt Installation zu beachten.
Benutzeroberfläche
Projektname: MediaCategorizer - UI
Repository: https://github.com/mastersign/mediacategorizer-ui/
Verzeichnis: /components/MediaCategorizer
Projekt-Typ: Microsoft Visual Studio
Programmiersprache: C# 5.0
Plattform, Bibliotheken: .NET 4.5, WPF, Xceed WPF-Toolkit, Windows API CodePack
Merkmale
- Einfache Bedienung
- Verwaltung eines Projektes (Medien, Kategorien, Parameter)
- Ansteuerung von FFmpeg, WaveViz, Transcripter und Distillery über die Befehlszeile
- Überwachung der Prozessausführung
Architektur
Der Quellcode der Benutzeroberfläche teilt sich in die folgenden Namensräume auf (siehe Abbildung 2).
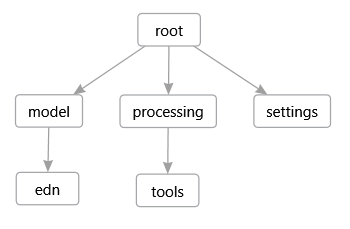
de.fhb.oll.mediacategorizer
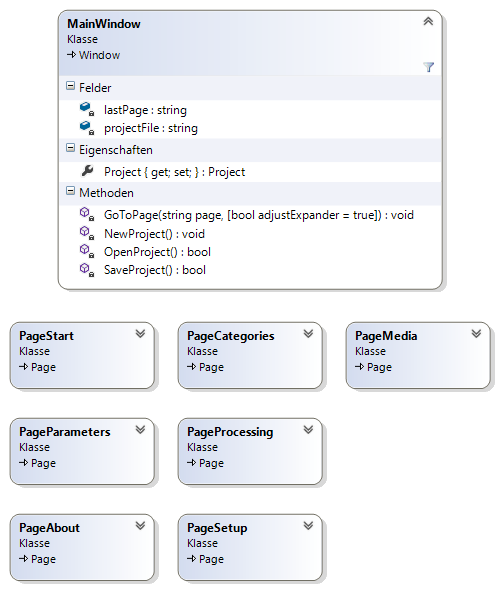
Dieser Namensraum enthält die App-Klasse welche den Programmstart initiiert, das Hauptfenster MainWindow und die verschiedenen Seiten Page* (siehe Abbildung 3).
de.fhb.oll.mediacategorizer.edn
Dieser Namensraum enthält die Schnittstelle IEdnWritable und einige Hilfsklassen für das Erzeugen von EDN-Dateien.
de.fhb.oll.mediacategorizer.model
Dieser Namensraum enthält die Domain-Modell-Klassen Project, Category, Media, Configuration und alle Klassen die für deren Definition benötigt werden (siehe Abbildung 4 und Abbildung 5).
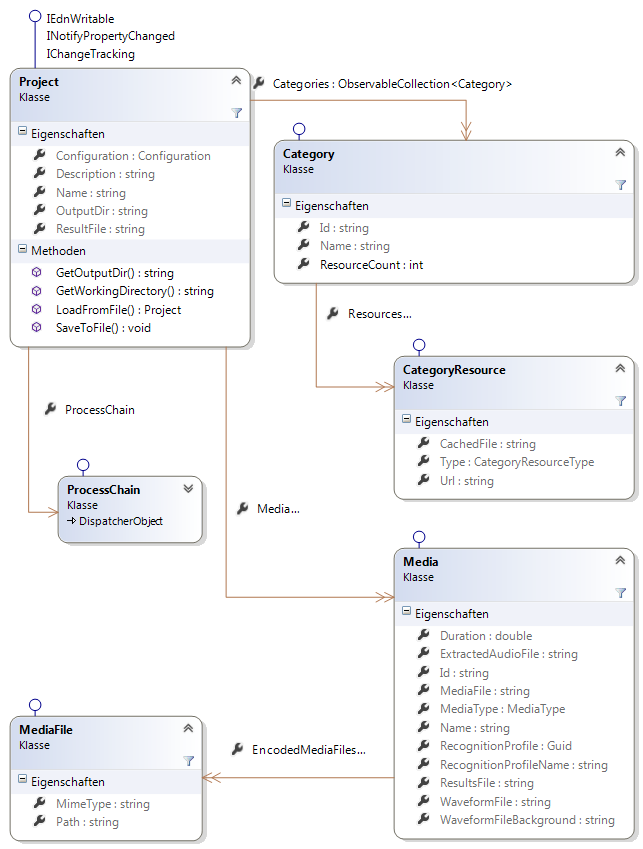
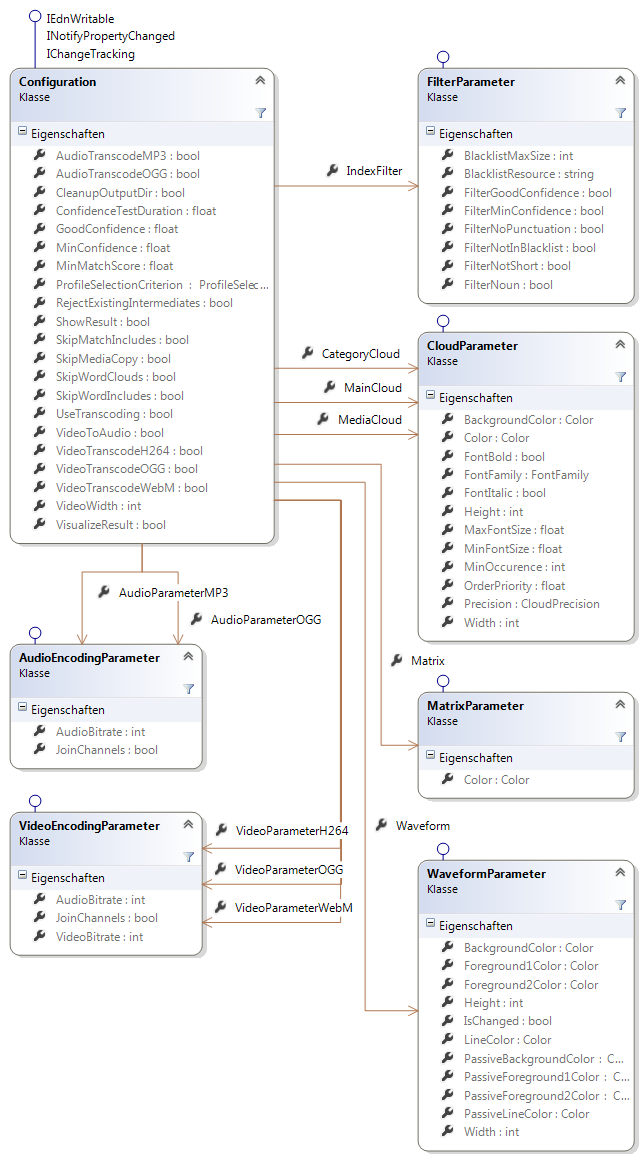
Die Klassen in diesem Namensraum wird in der Datei Model.xml definiert und durch den Codegenerator Scaleton in der Datei Model.Designer.cs implementiert. Einige der generierten Klassen werden in eigenen Dateien um zusätzliche Funktionalität ergänzt. Die Schnittstelle IEdnWritable wird für alle Modell-Klassen in der Datei <abbr title="Extensible Data Notation">EDN</abbr>.cs implementiert.
de.fhb.oll.mediacategorizer.processing
Dieser Namensraum enthält die Klassen für die verschiedenen Prozessschritte. Jeder Prozessschritt wird durch eine Klasse realisiert, welche die Schnittstelle IProcess implementiert (siehe Abbildung 6). Zur Vereinfachung der Implementierung wurden gemeinsame Aspekte der Prozessschritte in den Basisklassen ProcessBase und MultiTaskProcessBase zusammengefasst (siehe Abbildung 7).
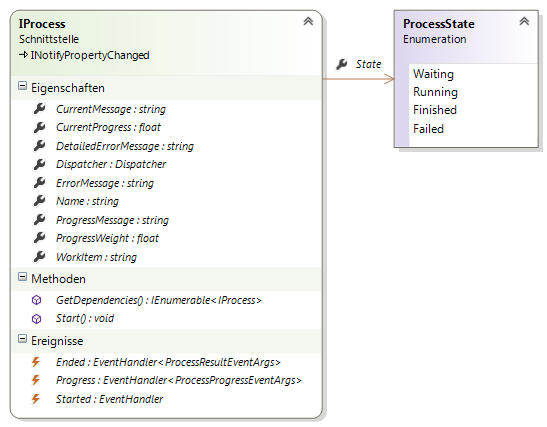
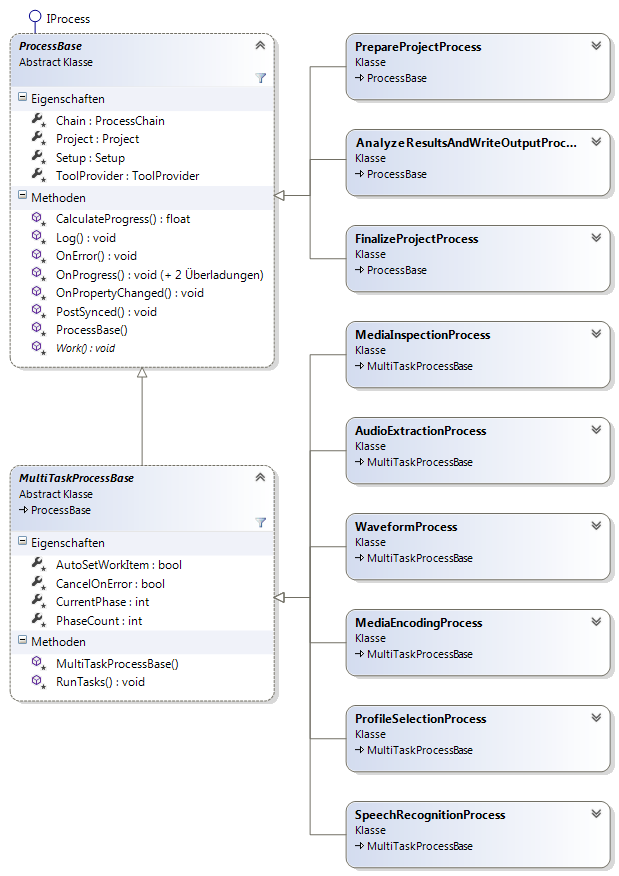
Die Klasse ProcessChain verwaltet den gesamten Prozess und übernimmt das Starten der Prozessschritte, wenn deren Vorgänger im Prozess erfolgreich abgeschlossen wurden (siehe Abbildung 8).
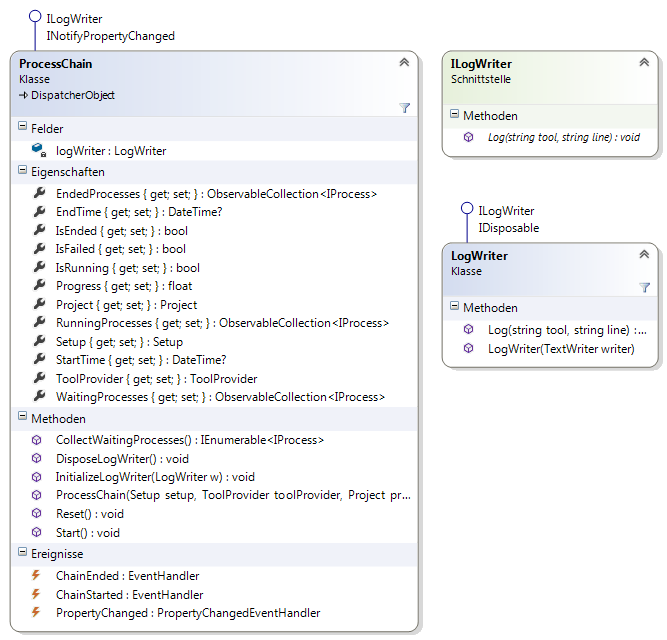
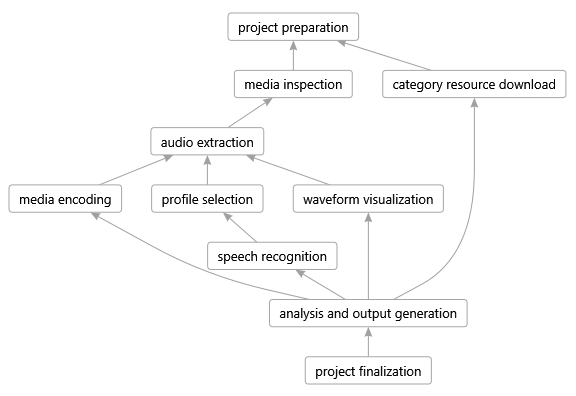
Wann welche Prozessschritte gestartet werden, hängt von deren Abhängigkeiten ab. Ein Prozessschritt wird genau dann gestartet, wenn alle Prozessschritte, von denen er abhängig ist, erfolgreich ausgeführt wurden. Prozessschritte ohne Abhängigkeiten werden mit dem Start des Gesamtprozesses gestartet. In Abbildung 9 sind die Abhängigkeiten zwischen den Prozessschritten visualisiert.
de.fhb.oll.mediacategorizer.tools
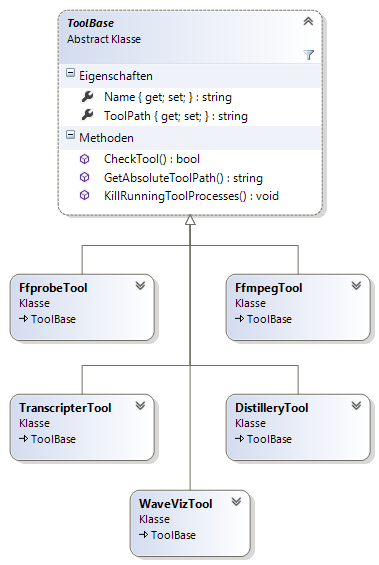
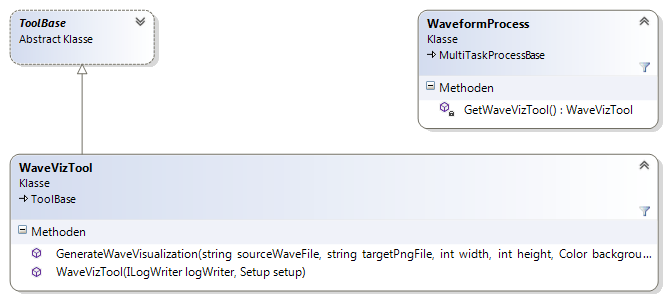
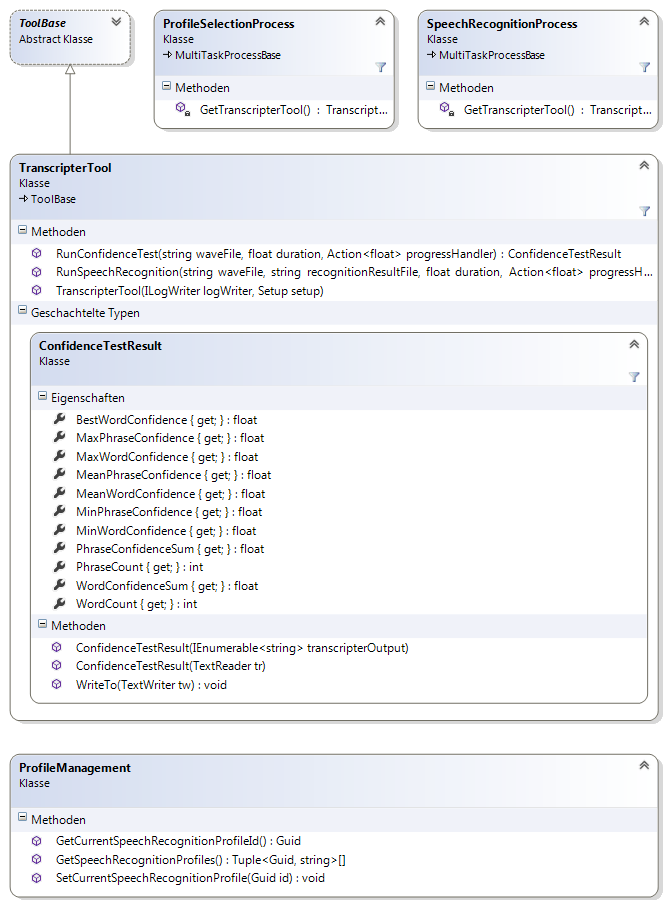
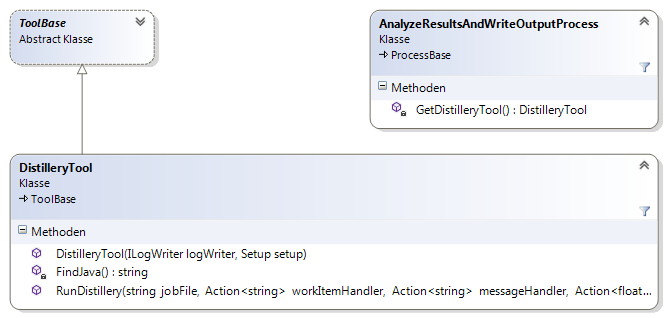
Dieser Namensraum enthält die Steuerklassen für die Komponenten, die über eine Befehlszeilenschnittstelle angesteuert werden. Die Steuerklassen sind von der gemeinsamen Basisklasse ToolBase abgeleitet (siehe Abbildung 10).
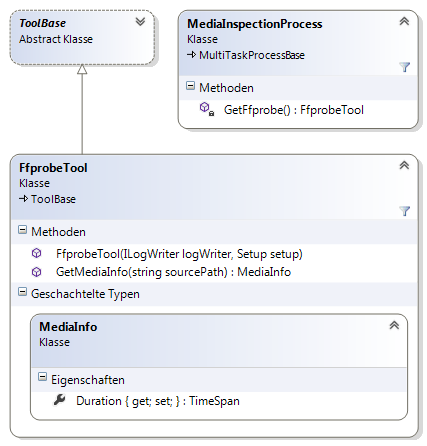
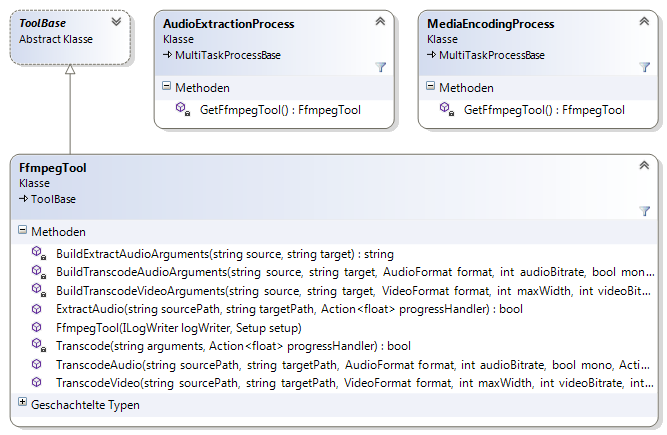
ToolFfprobe(siehe Abbildung 11)ToolFfmpeg(siehe Abbildung 12)ToolWaveViz(siehe Abbildung 13)ToolTranscripter(siehe Abbildung 14)ToolDistillery(siehe Abbildung 15)
Die Steuerklassen sind für das asynchrone Verarbeiten der Komponentenausgaben verantwortlich. Die Ausgaben enthalten dabei sowohl Fortschrittsinformationen als auch Ergebnisdaten.
de.fhb.oll.mediacategorizer.settings
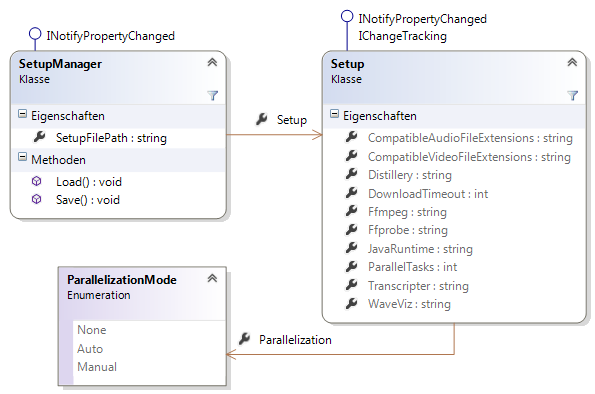
Dieser Namensraum enthält die Klassen Setup und SetupManager, die für die Verwaltung und das Sichern und Wiederherstellen der Anwendungseinstellungen verantwortlich sind (siehe Abbildung 16).
Medieninspektion und Tonspurextraktion (extern)
Projektname: FFmpeg
Website: http://www.ffmpeg.org
Merkmale
- Befehlszeilenschnittstelle
- Inspektion und Transformation von Audio- und Videodaten
Befehlszeilenschnittstelle
Das FFmpeg-Projekt umfasst die Programmdatei ffmpeg.exe für Transformationsaufgaben und die Programmdatei ffprobe.exe für Inspektionsaufgaben.
Inspektion
Beispiel: > ffprobe.exe -i "D:\media\video.mp4"
Die Ausgabe könnte dann z.B. wie folgt aussehen.
ffprobe version N-58699-ge3d7a39 Copyright (c) 2007-2013 the FFmpeg developers
built on Dec 1 2013 22:07:24 with gcc 4.8.2 (GCC)
configuration: --enable-gpl --enable-version3 --disable-w32threads --enable-avisynth --enable-bzlib --enable-fontconfig --enable-frei0r --enable-gnutls --enable-iconv --enable-libass --enable-libbluray --enable-libcaca --enable-libfreetype --enable-libgsm --enable-libilbc --enable-libmodplug --enable-libmp3lame --enable-libopencore-amrnb --enable-libopencore-amrwb --enable-libopenjpeg --enable-libopus --enable-librtmp --enable-libschroedinger --enable-libsoxr --enable-libspeex --enable-libtheora --enable-libtwolame --enable-libvidstab --enable-libvo-aacenc --enable-libvo-amrwbenc --enable-libvorbis --enable-libvpx --enable-libwavpack --enable-libx264 --enable-libxavs --enable-libxvid --enable-zlib
libavutil 52. 56.100 / 52. 56.100
libavcodec 55. 44.100 / 55. 44.100
libavformat 55. 22.100 / 55. 22.100
libavdevice 55. 5.102 / 55. 5.102
libavfilter 3. 91.100 / 3. 91.100
libswscale 2. 5.101 / 2. 5.101
libswresample 0. 17.104 / 0. 17.104
libpostproc 52. 3.100 / 52. 3.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'D:\media\video.mp4':
Metadata:
major_brand : mp42
minor_version : 0
compatible_brands: isommp42
creation_time : 2012-05-15 16:52:11
Duration: 01:05:51.97, start: 0.000000, bitrate: 363 kb/s
Stream #0:0(und): Video: h264 (Constrained Baseline) (avc1 / 0x31637661), yuv420p, 480x360, 265 kb/s, 18 fps, 18 tbr, 36 tbn, 36 tbc (default)
Metadata:
creation_time : 1970-01-01 00:00:00
handler_name : VideoHandler
Stream #0:1(und): Audio: aac (mp4a / 0x6134706D), 44100 Hz, stereo, fltp, 95 kb/s (default)
Metadata:
creation_time : 2012-05-15 16:52:11
handler_name : IsoMedia File Produced by Google, 5-11-2011MediaCategorizer nutzt ffprobe um die Länge der Mediums zu ermitteln, um daraus einen Fortschritt bei Transformation und Spracherkennung zu berechnen. Die Länge des Mediums wird dabei mit dem folgenden regulären Ausdruck ermittelt: Duration: (\d+):(\d\d):(\d\d)\.(\d+). Die vier Gruppen entsprechen dabei Stunden, Minuten, Sekunden, Millisekunden.
Transformation
Beispiel: > ffmpeg.exe -i "D:\media\video.mp4" -n -vn -ac 1 -ar 16000 -acodec pcm_s16le "D:\media\sound.wav"
Bedeutung der Argumente:
-i "D:\media\video.mp4"Der Pfad der Eingabedatei-nAbbrechen falls Ausgabedatei bereits existiert-vnkeine Videoausgabe-ac 11-kanalige Audioausgabe (mono)-ar 16000Resampling der Abtastrate auf 16 kHz-acodec pcm_s16leAusgabeformat ist PCM-Audio mit Vorzeichen-behafteter 16Bit-Auflösung und Little-Endian Byte-Reihenfolge"D:\media\sound.wavDer Pfad der Ausgabedatei
Wellenformvisualisierung (extern)
Projektname: WaveViz
Repository: https://github.com/mastersign/waveviz
Merkmale
- Befehlszeilenschnittstelle
- Erwartet PCM-Wave-Dateien (16 Bit, mono, Abtastrate beliebig)
- Parameter für die Größe der Bildfläche
- Parameter für Hintergrund und Vordergrundfarben
- Antialiasing durch Over-Sampling
- Ausgabe als PNG-Datei

Befehlszeilenschnittstelle
Programmdatei: WaveViz.exe
Syntax: waveviz <WAV-Datei> <PNG-Datei> [w h] [bg f1 f2 li]
w = Bildbreite in Pixeln
h = Bildhöhe in Pixeln
bg = Hintergrundfarbe
f1 = Vordergrundfarbe 1
f2 = Vordergrundfarbe 2
li = Farbe der Horizontlinie
Farbwerte werden als RGBA-Hex-Werte angegeben. (z.B. #E080D0FF)Beispiel: > WaveViz.exe "D:\media\sound.wav" "D:\media\wave.png" 1024 100 #00000000 #FF880080 #880000FF #FF0000FF
Spracherkennung
Projektname: MediaCategorizer - Transcripter
Repository: https://github.com/mastersign/mediacategorizer-transcripter/
Verzeichnis: /components/Transcripter
Projekt-Typ: Microsoft Visual Studio
Programmiersprache: C# 5.0
Plattform, Bibiotheken: .NET 4.5, Microsoft Speech API
Merkmale
- Befehlszeilenschnittstelle
- Ansteuerung der Microsoft Speech API
über den .NET-NamensraumSystem.Speech.Recognitionaus der AssemblySystem.Speech.dll - Ausgabe der Erkennungsergebnisse als EDN-Datei
Architektur
Das Befehlszeilenprogramm Transcripter ist nahezu vollständig prozedural in der statischen Klasse de.fhb.oll.transcripter.Program implementiert. Lediglich das Parsen der Befehlszeilenargumente wird von einer Instanz der Klasse CommandLineArguments übernommen.
Das Programm besitzt zwei Betriebsmodi. Im Standardmodus wird die gesamte Quelldatei vom Spracherkennungssystem verarbeitet und die Erkennungsergebnisse werden im EDN-Format in die Ergebnisdatei geschrieben. Die Ergebnisdatei sollte die Endung .srr für Speech Recognition Result besitzen. Im Testmodus für Erkennungssicherheit wird nur der Anfang einer Datei vom Spracherkennungssystem verarbeitet und statistische Werte zu den erkannten Phrasen und Wörtern ausgegeben.
Befehlszeilenschnittstelle
Programmdatei: Transcripter.exe
Syntax: transcripter [Optionen] <WAV-Datei>
Optionen
-ct, --confidence-test: Schaltet in den Testmodus für Erkennungssicherheit
-td, --test-duration: Die maximale Testlänge ab dem Dateianfang in Sekunden
-db, --dashboard: Aktiviert im Standardmodus eine Übersichtsdarstellung
-p, --progress: Aktiviert die Ausgabe des Fortschritts
-t, --target <SRR-Datei>: Gibt im Standardmodus die Ergebnisdatei anBeispiel Test: > Transcripter.exe -ct -td 60 "D:\media\sound.wav"
Beispiel Spracherkennung: > Transcripter.exe -p -t "D:\media\result.srr" "D:\media\sound.wav"
Testergebnisse
Im Testmodus für Erkennungssicherheit werden die folgenden Werte ausgegeben.
PhraseCountAnzahl der erkannten PhrasenPhraseConfidenceSumSumme der Erkennungssicherheit aller erkannten PhrasenMaxPhraseConfidenceHöchste Erkennungssicherheit aller erkannten PhrasenMinPhraseConfidenceMittlere Erkennungssicherheit aller erkannten PhrasenMinPhraseConfidenceGeringste Erkennungssicherheit aller erkannten PhrasenWordCountAnzahl der erkannten WorteWordCondifenceSumSumme der Erkennungssicherheit aller erkannten WorteMaxWordConfidenceHöchste Erkennungssicherheit aller erkannten WorteMeanWordConfidenceMittlere Erkennungssicherheit aller erkannten WorteMinWordConfidenceGeringste Erkennungssicherheit aller erkannten WorteBestWordConfidenceMittlere Erkennungssicherheit des am besten erkannten Wortes
Analyse und Visualisierung
Projektname: MediaCategorizer - Distillery
Repository: https://github.com/mastersign/mediacategorizer-distillery/
Verzeichnis: /components/Distillery
Projekt-Typ: Leiningen
Programmiersprache: Clojure 1.5
Plattform, Bibiotheken: Java 7 Runtime, clojure, data.xml, enlive
Merkmale
- Befehlszeilenschnittstelle
- Analyse der Spracherkennungsergebnisse
- Erzeugung der Worthäufigkeitslisten für Medien und Kategorien
- Berechnung der Übereinstimmungskennzahlen
- Erzeugung der XML-Ausgabe
- Erzeugung der Reintext-Ausgabe
- Ansteuerung der Bibliothek Mastersign Cloud
- Erzeugung der Ergebniswebseite
Architektur
Distillery ist nach dem funktionalen Programmierparadigma entwickelt und besteht aus einer Anzahl von Namensräumen und Funktionen in diesen Namensräumen. Es wurden keine expliziten Datentypen definiert, sondern ausschließlich die nativen Datentypen von Clojure verwendet (siehe Intermediate Data Structures).
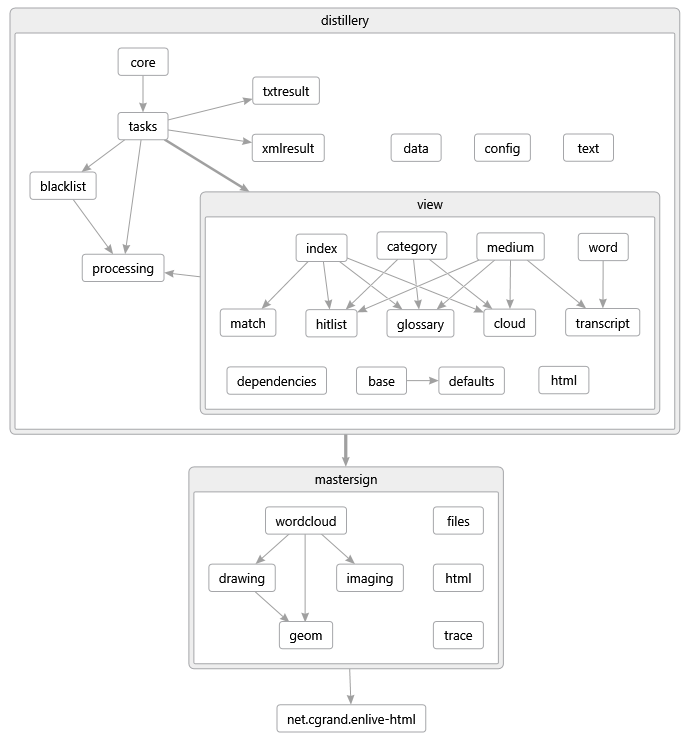
In Abbildung 18 werden die Namensräume und ihre Abhängigkeiten dargestellt. Der Einstiegspunkt für die Anwendung ist der Namensraum distillery.core. Die logischen Schritte der Verarbeitung und die Ausgabe der Fortschrittsmeldungen sind in distillery.tasks implementiert. Die Funktionen für die Analyse der Spracherkennungsergebnisse befinden sich im Namensraum distillery.processing. Die Namensräume distillery.txtresult und distillery.xmlresult enthalten Funktionen zur Ausgabe der Spracherkennungs- und Analyseergebnisse in Reintext und XML-Format. Die Namensräume in distillery.view enthalten die verschiedenen Teile für die Erzeugung der HTML5-Webseite.
Ergänzend gibt es die Namensräume distillery.data, distillery.text und distillery.config. Der Namesraum distillery.data enthält Funktionen für das Laden von externen Daten (z.B. Web-Seiten oder Textdateien) und einige allgemeine Hilfsfunktionen als Ergänzung zur clojure.core-Bibliothek. Der Namensraum distillery.text ist eine Abstraktionsschicht für Zeichenfolgenkonstanten, welche aus der Datei Distillery/resources/text.edn geladen werden. Diese Zwischenschicht bietet die Grundlage für die Wiederverwendung von Zeichenfolgen und stellt eine Vorbereitung für die Unterstützung von mehreren Ausgabesprachen dar. Der Namensraum distillery.config bietet eine Funktion für das Laden von Konfigurationsparametern an. Dabei werden Standardwerte aus der Datei Distillery/resources/default-config.edn geladen und mit den benutzerdefinierten Konfigurationsparameters aus der Job-Datei überlagert.
API
Für eine ausführliche Beschreibung der Namensräume und Funktionen von Distillery steht die automatisch generierte API-Dokumentation im Verzeichnis Distillery/doc/api.html zur Verfügung.
Befehlszeile
Programmdatei: distillery.jar
Die Einstiegsfunktion von Distillery erwartet nur den Pfad zur Job-Datei als einziges Argument.
Beispiel: > java -jar "D:\MediaCategorizer\tools\distillery.jar" "D:\work\job.saj"
Wortwolken
Projektname: Mastersign Cloud
Repository: https://github.com/mastersign/mediacategorizer-distillery/
Verzeichnis: /components/Distillery/src/mastersign
Projekt-Typ: Clojure-Bibliothek
Programmiersprache: Clojure 1.5
Plattform, Bibliotheken: Java 7 Runtime, clojure
Merkmale
- Clojure-Schnittstelle
- Visualisierung einer Wortmenge
- Unterstützung für zwei charakteristische Größen (Wortgröße, Farbe)
- Parameter für die Größe der Bildfläche
- Parameter für Hintergrund- und Vordergrundfarben
- Parameter für Schriftgrößen und -stilen
- Optional sortiertes Layout
- Parametrisierung für Darstellungsqualität (beeinflusst Laufzeit)
API
Die Funktionen des Wortwolkengenerators befinden sich in dem Namensraum mastersign.wordcloud. Um eine Wortwolke zu erzeugen, sind die folgenden Schritte notwendig.
- Sortieren der Wortliste, Zuweisen von Schriftart, Schriftgröße und Schriftfarbe, und Berechnen des Platzbedarfs der einzelnen Worte
- Berechnen der Position und Drehung aller Wörter die auf die Bildfläche passen
- Zeichnen der Wörter an den berechneten Position im entsprechenden Stil
Um den ersten Schritt auszuführen, wird die Funktion mastersign.wordcloud/build-word-infos aufgerufen. Diese nimmt zwei Parameter entgegen: word-data und args. Das Argument word-data erwartet eine Sequenz von Vektoren/Tupeln mit folgendem Aufbau: [id text v1 v2] wobei id eine Zeichenkette zur eindeutigen Identifizierung des Wortes ist, text die darzustellende Zeichenfolge des Wortes, v1 die Wert für die Schriftgröße und v2 der Wert für die Schriftfarbe. Die Werte v1 und v2 sollten im Wertebereich [0..1] liegen. Ein Beispieldatensatz könnt z.B. wie folgt aussehen.
(def words [["b" "Bravo" 0.1 0.9]
["a" "Alpha" 0.4 0.8]
["c" "Charlie" 1.0 0.2]
...])Das Argument args erwartet eine Map mit den folgenden Slots:
:order-modesteuert, nach welcher Worteigenschaft sortiert werden soll (:id,:text,:value1,:value2) (Standard::value1)
Die Sortierung wirkt sich später in der Position der Worte aus. Worte die am Anfang eingeordnet werde, erscheinen tendenziell in der Mitte der Wolke, Worte die am Ende eingeordnet werden, erscheinen tendenziell am Rand der Wolke.:fontDie Schriftart (mit Schriftfamilie und -stil):java.awt.Font:color-fnEine Funktion, die einen Wert zwischen 0 und 1 auf einejava.awt.Color-Instanz abbildet (Standard: Eine Überblendung zwischen Blau und Orange):min-font-sizeDie kleinste zu verwendende Schriftgröße in Pixeln (Standard:14):max-font-sizeDie größte zu verwendende Schriftgröße in Pixeln (Standard:80)
Ein Aufruf könnte z.B. wie folgt aussehen.
(def word-infos (build-word-infos words {:order-mode :value2}))Wird anstelle der Standardsortierung von :value1 die Sortierung :value2 angegeben wird nicht nach Wortgröße sondern nach Farbe sortiert (siehe Abbildung 20).
Das Ergebnis des Aufrufs ist eine Sequenz mit Maps als Elementen. Jedes Element besitzt dabei die folgenden Slots:
:idDie Id:textDie Zeichenfolge:v1Der erste Wert:v2Der zweite Wert:fontDie Schriftart (mit Schriftfamilie, -größe und -stil):java.awt.Font:colorDie Farbe:java.awt.Color:word-boundsDas Rechteck in dem alle Zeichen des Wortes Platz finden:java.awt.geom.Rectangle2D.Float:glyph-boundsEin Vektor mit den Rechtecken in denen sich die einzelnen Zeichen des Wortes befinden: Vektor vonjava.awt.geom.Rectangle2D.Float
Für den zweiten Schritt wird die Funktion mastersign.wordcloud/build-cloud-info aufgerufen. Sie akzeptiert ebenfalls zwei Argumente: word-infos und args. Das Argument word-infos erwartet die Sequenz von Wortbeschreibungen in Form von Maps wie sie von build-word-infos zurückgegeben wird. Das zweite Argument erwartet eine Map, die die folgenden Steuerparameter enthalten muss:
:widthDie Breite der Bildfläche in Pixeln (Standard:600):heightDie Höhe der Bildfläche in Pixeln (Standard:300):paddingDer minimale Randabstand zum Bildrand (Standard:4):max-test-radiusDer maximale Abstand zum Mittelpunkt beim Suchen einer passenden Position (Standard:350):order-priorityEin Wert zwischen 0 und 1 der angibt, wie stark eine alphabetische Sortierung angewendet werden soll (Standard:0.7):allow-rotationGibt an, ob Worte nach rechts oder links gedreht werden dürfen (Standard:true):precisionGibt die Präzision bei der Positionssuche als Wert zwischen 0 und 1 an (Standard:0.4):final-refineGibt an, ob die Worte nach der Positionierung zusammengerückt werden sollen (Standard:true)
Ein Aufruf könnte z.B. wie folgt aussehen.
(def cloud-info (build-cloud-info word-infos {:width 400 :height 400 :precision 0.7}))Das Ergebnis des Aufrufs ist eine Map mit den folgenden Slots:
:argsDie übergebene Map mit den Steuerparametern:word-infosDie übergebene Sequenz mit den Wortbeschreibungen, wobei die Wortbeschreibungen um die folgenden Slots ergänzt wurden::positionMittelpunkt des Wortes:rotationAusrichtung des Wortes:rectDas Rechteck in dem das Wort platziert wurde
:test-areaDer Bereich der Bildfläche, der mit Worten gefüllt wurde
Der dritte Schritt ist das Zeichnen der Wortwolke. Dazu wird die Funktion mastersign.wordcloud/paint-cloud aufgerufen. Sie akzeptiert als erstes Argument eine Map mit der Beschreibung der Wortwolke, wie sie von mastersign.wordcloud/build-cloud-info zurückgegeben wird. Als zweites Argument akzeptiert sie eine Map mit Steuerparametern, welche die Slots :width und :height enthalten muss. Die Funktion gibt ein java.awt.image.BufferedImage zurück.
Der Aufruf könnte z.B. wie folgt aussehen.
(def img (paint-cloud cloud-info {:width 400 :height 400}))Als Zusammenfassung der drei Schritte und Vereinfachung des Aufrufs kann die Funktion mastersign.wordcloud/create-cloud verwendet werden. Sie erwartet als erstes Argument eine Sequenz mit Wörtern in der Form wie sie mastersign.wordcloud/build-word-info erwartet. Als zusätzliche Argumente können alle Steuerparameter aus den oben genannten Maps mit dem Argumentnamen args verwendet werden.
Ein Aufruf könnte z.B. wie folgt aussehen.
(def img (create-cloud words :width 400 :height 400 :precision 0.7 :order-mode :value2))Die folgenden Abbildungen zeigen mögliche Ergebnisse.


